The industry's fastest realtime multimodal AI system with 'real response' delivers 'true comfort' and 'complete privacy'.
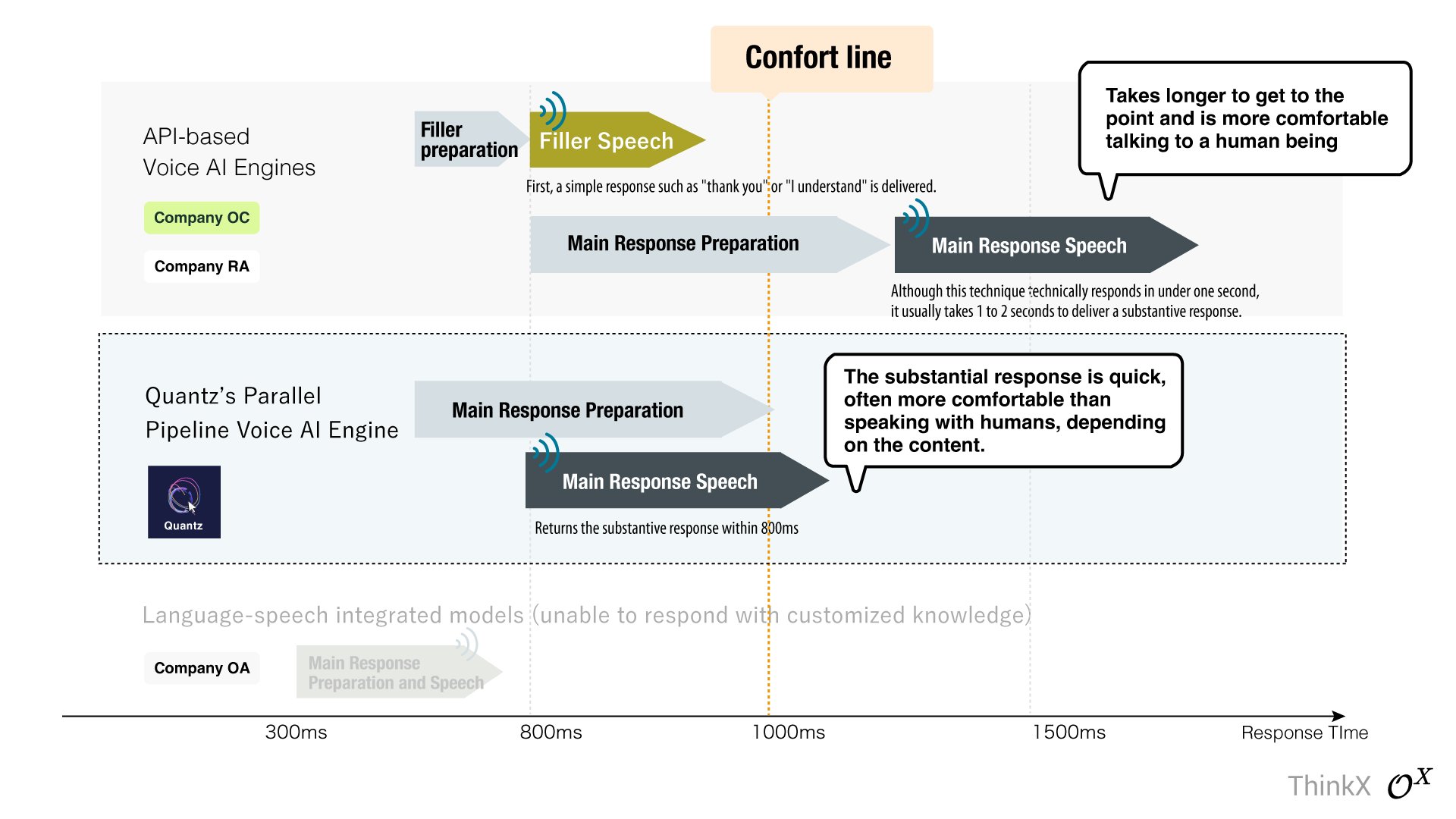
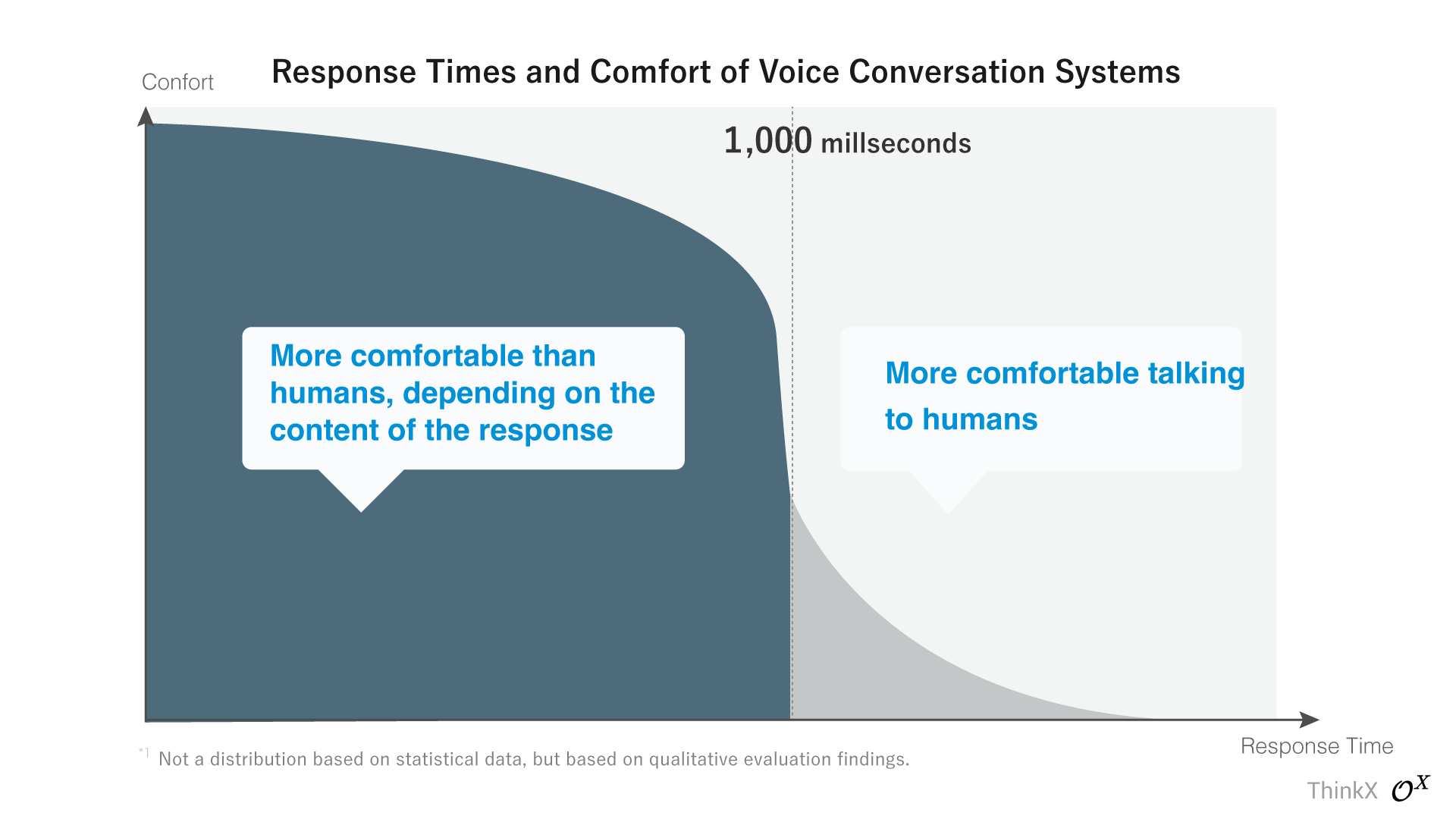
Quantz ® Voice-AI OS immediately delivers the substantive response, achieving a response time of just 800ms, avoiding the common 'filler technique' that relies on simple responses like 'thank you'.
Many typical API-based voice AI engines struggle to exceed the 'one-second barrier' and resort to using the 'filler technique'. This involves issuing a preliminary response such as 'thank you' or 'I understand' while the main response is being prepared. Although this approach may achieve a numerical response time of less than one second, it takes 1 to 2 seconds before the main topic is addressed, which can be frustrating during longer interactions.
Quantz ® Voice-AI OS is a groundbreaking real-time multimodal system based on LLM that eschews this technique, delivering the main topic—the real response—within 800ms, without using any external API.
Exceeds the One-Second Barrier in a "Real Response" Time
Quantz® Voice-AI OS is designed for 'true comfort', based on a proprietary codebase of 670,000 lines, including 4 patented technologies, 2 of which are pending.
It features a massive parallelism of the NLP (natural language processing) and speech processing pipelines, with a unix-socket based unique byte transfer protocol that reduces the overhead of TCP/IP communication and allows large amounts of data transfer to be completed on a single server.
The system is powered by dedicated GPU supercomputers managed by ThinkX, ensuring robust performance in a highly secure facility.
Our GPU Cluster ThinkX Supercom3
Voice-AI OS optimized for 'True Comfort', running on an in-house managed high-performance GPU computer cluster with a proprietary codebase of 670,000 lines
Quantz ® Voice-AI OS is built on physical servers in data centres with high security requirements and does not use any external APIs such as ChatGPT API, Eleven Labs API, etc. (Models fine-tuned from the open source LLM Meta Llama3 are executed with 100~ parallel/GPU [2500 tokens~/sec] inference by a proprietary implementation of the LLM Parallel Inference Adapter).
This ensures the highest level of privacy protection and security for system users by not exposing critical, conversational information to external companies.
Highest Level of Data Security and Privacy—No External APIs, No Outgoing Conversational Data
Unlike integrated type multimodal AI systems that rely on a single LLM for voice and language processing, our architecture separates each model and process. This separation enables flexible customization of the pipeline, including mid-response monitoring and switching between utterances, all while maintaining potential for scalability and achieving high performance.
Modularized Language and Speech Models: Scalable and Customizable Pipeline
Quantz ® Voice-AI OS operates on dedicated physical servers, ensuring unparalleled data security by eliminating reliance on external APIs. This setup guarantees that no conversational data is transmitted externally, upholding the strictest privacy standards.
"Where Answers Arrive at the Speed of Thought"—Quantz delivers this promise through the intelligence of state-of-the-art LLM. Speak less and solve more with Quantz; it understands even the most concise queries and provides precise, to-the-point answers. It effortlessly handles complex, long sentences of over 30 words and delivers responses within an impressive 800ms.
Quantz ® Voice-AI OS strikes the optimum balance between customisation flexibility, stringent privacy standards and 'true comfort', providing fast and real responses to enhance user experience.
 Our GPU Cluster ThinkX Supercom3
Our GPU Cluster ThinkX Supercom3
