<<
Advisor Interview: Toward a High-Speed Computing Platform for Everyone—ThinkX and Tohoku University Envision Supercomputing with AI and FPGA: Interview with Professor Masanori Hariyama
February 19, 2025
Masanori Hariyama, Professor of Intelligent Integrated Systems, Graduate School of Information Sciences, Tohoku University
This time, we spoke with Professor Masanori Hariyama from the Intelligent Integrated Systems field at Tohoku University, a leading expert in the applied research of FPGA (Field Programmable Gate Array) semiconductors—a type of integrated circuit for supercomputing—and an advisor to ThinkX.


 Masanori Hariyama
Masanori Hariyama
Ph.D. (Information Science). Professor at the Graduate School of Information Sciences, Intelligent Integrated Systems, Tohoku University. A leading expert in Japan on application-specific supercomputing using FPGA (Field-Programmable Gate Arrays).
Kazuki Otsuka (hereinafter Otsuka)
Today, we are speaking with Professor Masanori Hariyama from Tohoku University, a collaborator and advisor on ThinkX’s project 'Dynamic Accelerator*1 System for Real-Time Big Data Analysis in Advanced Research'—or, in simpler terms, 'a supercomputer powered by AI and specialized semiconductors.'
This project is being developed as a key feature of the VN Machine Cloud, a computing platform for advanced research. The goal is to democratize complex data processing. Think of tasks like handling endless streams of images from giant telescopes (imagine terabytes of star data), real-time analysis for quantum chemistry, and DNA sequencing. Currently, experts custom-build these solutions, but our aim is to fling that door wide open. Imagine researchers without computing expertise finishing calculations that take six months in just three days or cutting electricity costs in half. We believe this solution holds particular value for large-scale, interdisciplinary challenges like climate modeling or sustainable energy.
To start, Professor Hariyama, could you tell us about your expertise and recent projects?
This project is being developed as a key feature of the VN Machine Cloud, a computing platform for advanced research. The goal is to democratize complex data processing. Think of tasks like handling endless streams of images from giant telescopes (imagine terabytes of star data), real-time analysis for quantum chemistry, and DNA sequencing. Currently, experts custom-build these solutions, but our aim is to fling that door wide open. Imagine researchers without computing expertise finishing calculations that take six months in just three days or cutting electricity costs in half. We believe this solution holds particular value for large-scale, interdisciplinary challenges like climate modeling or sustainable energy.
To start, Professor Hariyama, could you tell us about your expertise and recent projects?
Professor Masanori Hariyama (hereinafter Hariyama)
My expertise lies in application-specific supercomputers using FPGAs. FPGA stands for Field-Programmable Gate Arrays. It’s a type of semiconductor that can be reprogrammed after manufacturing by altering its circuitry or computational functions through programming. This flexibility makes it useful when, for instance, you need to speed up specific processes or reduce power consumption. Moreover, by changing the program, FPGAs can adapt to various applications, allowing mass production of a single chip type, which significantly cuts manufacturing costs.
Examples of our developments include solvers for quantum annealing, simulations of gate-based quantum computers, natural language processing, and DNA sequencers.
While FPGAs offer these advantages, designing circuits optimized for specific applications isn’t always straightforward, unlike general-purpose CPUs or GPUs.
Examples of our developments include solvers for quantum annealing, simulations of gate-based quantum computers, natural language processing, and DNA sequencers.
While FPGAs offer these advantages, designing circuits optimized for specific applications isn’t always straightforward, unlike general-purpose CPUs or GPUs.
Real-time processing of the H.266 encoding/decoding algorithm on large video files. (Image provided by: Hariyama Laboratory)
Otsuka
FPGA technology has come a long way, hasn’t it? Xilinx was acquired in 2012, and Altera in 2022. Our approach combines FPGAs with large-scale language models—AI, essentially—to identify standardized computational patterns. Instead of writing everything in detailed languages like OpenCL or C++, we’re building a higher-level language. The idea is to automate the process so the system figures out the right way to apply computations on its own. Could you explain in detail how that works with FPGAs?
Hariyama
Optimization in FPGA computing boils down to two major patterns: spatial parallelism and pipelining. Spatial parallelism is like having multiple workers doing the same task concurrently—several units perform the same task on different data simultaneously. Pipelining, on the other hand, is like a factory assembly line: one worker passes results to the next, with each handling a different task, allowing multiple tasks to run in parallel. In practice, we combine these to create beneficial architectural patterns. For example, we might use spatial parallelism within a pipeline stage or nest pipelines within spatial parallelism. The key is finding the optimal combination of these patterns for a given job.
In actual design, we break the entire process into tasks and decide which are best suited for CPUs, GPUs, or FPGAs. To do this, we analyze each task’s parallelism, how much it can be parallelized, and how dependent one step is on another. From experience, we’ve found that task processing patterns fall into a few categories. We start with architecture templates based on these patterns—like blueprints—and fine-tune from there.
In actual design, we break the entire process into tasks and decide which are best suited for CPUs, GPUs, or FPGAs. To do this, we analyze each task’s parallelism, how much it can be parallelized, and how dependent one step is on another. From experience, we’ve found that task processing patterns fall into a few categories. We start with architecture templates based on these patterns—like blueprints—and fine-tune from there.
Scaling up to large datasets by linking chips together. (Image provided by: Hariyama Laboratory)
Otsuka
So, even if patterns are somewhat standardized, fine-tuning is still needed for specific tasks. What are the bottlenecks in making that tuning smoother?
Hariyama
It depends on constraints like how much data comes in at once and how fast it needs to be processed. We program the system to look at incoming data and decide, 'For this workload, optimize this way.' If the data flow is heavy, we deepen the pipeline; if it’s broad, we add more spatial units. With enough of this logic built in, the system can adapt and adjust automatically. Synthesizing FPGA circuits from C code can take around 10 hours in some cases. To reduce this compilation time, we’re collaborating with Altera Japan, integrating partial reconfiguration into OneAPI*2 and providing technical contributions to streamline FPGA design.
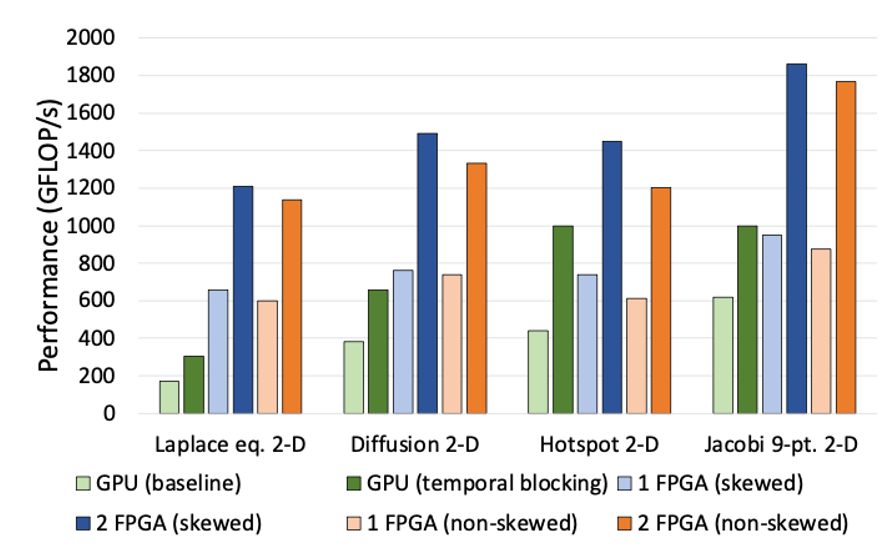
Benchmark comparison with GPUs. Connecting multiple FPGAs results in linear performance improvements, surpassing GPU capabilities with just two units. (Image provided by: Hariyama Laboratory)
Otsuka
Another thing I think is worth noting is the scalability of linking FPGAs. Connecting multiple chips makes them function like one giant circuit, right? In our cloud setup, this means we provide computing instances where users can leverage this across multiple units. What developments do you foresee?
Hariyama
One of FPGA’s strengths is how easy it is to scale up—just connect them with cables and tweak the setup. This isn’t widely known. For example, with massive graph structures, huge matrix calculations for climate models (think 10,000 x 10,000 grids), or quadruple-precision computations for quantum chemistry dealing with numbers from trillionths to trillions, CPUs and GPUs slow down as problems grow. But with FPGAs, connecting multiple units with cables makes them act like one giant chip. It’s nearly seamless, and speed doesn’t drop as scale increases. For scientific computing or specialized tasks, this is revolutionary.
Otsuka
Absolutely. Professor Hariyama, thank you for this valuable discussion. We look forward to continued collaboration.
*1 Dynamic Accelerator: Technology that dynamically reconfigures processor setups based on computation needs, improving speed and power efficiency.
*2 OneAPI: An open language for hardware programming developed by Intel.
*2 OneAPI: An open language for hardware programming developed by Intel.
Masanori HariyamaPh.D. (Information Science). Professor at the Graduate School of Information Sciences, Intelligent Integrated Systems, Tohoku University. A leading expert in Japan on application-specific supercomputing using FPGA (Field-Programmable Gate Arrays).