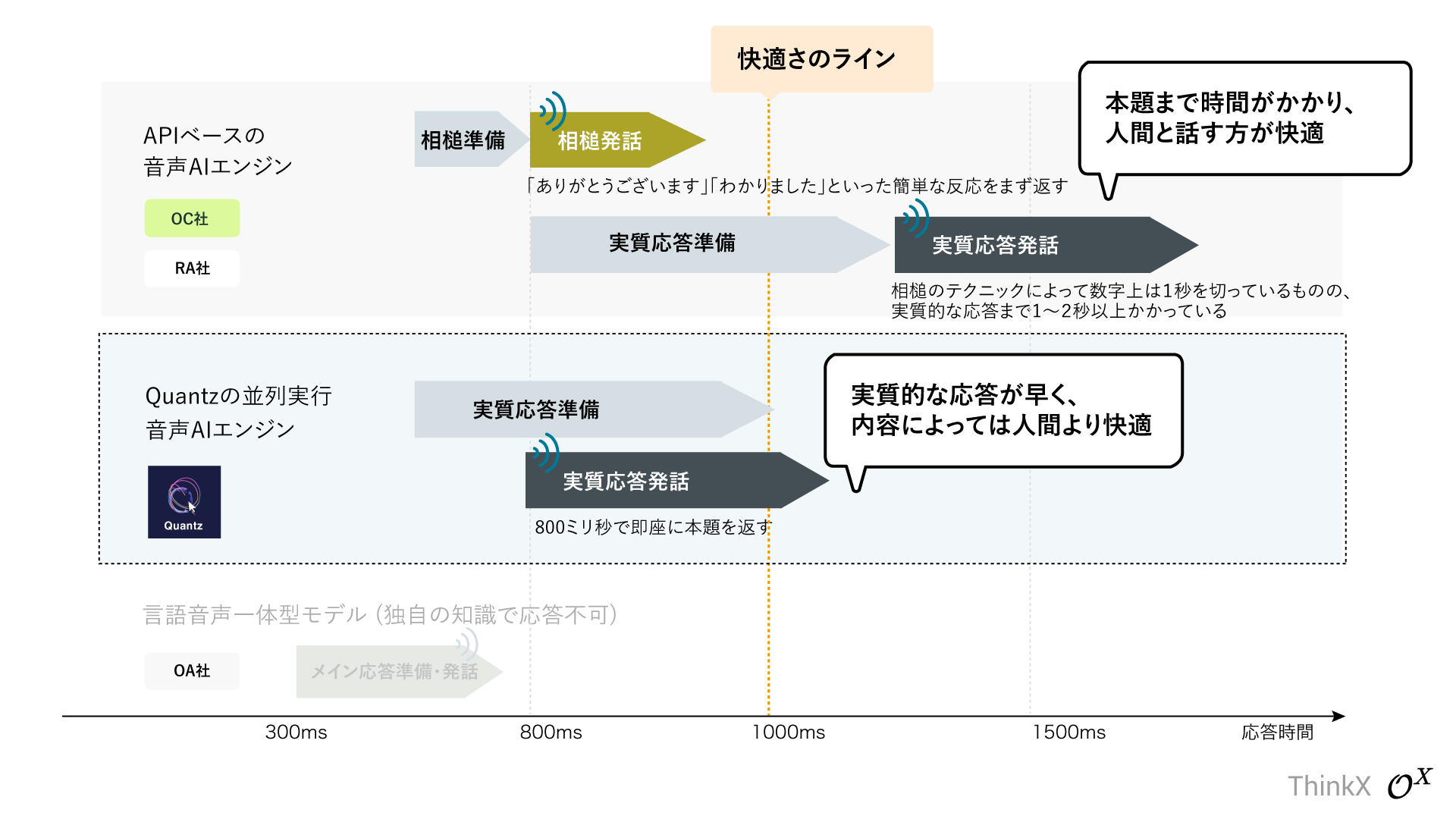
即座に本題(実質的な応答)を返し、「ありがとう」のような簡易的な応答テクニックを使用することなく800ms未満の応答速度を実現。
一般的なAPIベースの音声対話エンジンは"1秒の壁"を超えることが難しく、「ありがとうございます」「わかりました」といった予備的な応答をまず返し、その間にメインの応答を準備する「フィラー(相槌)テクニック」が用いられます。
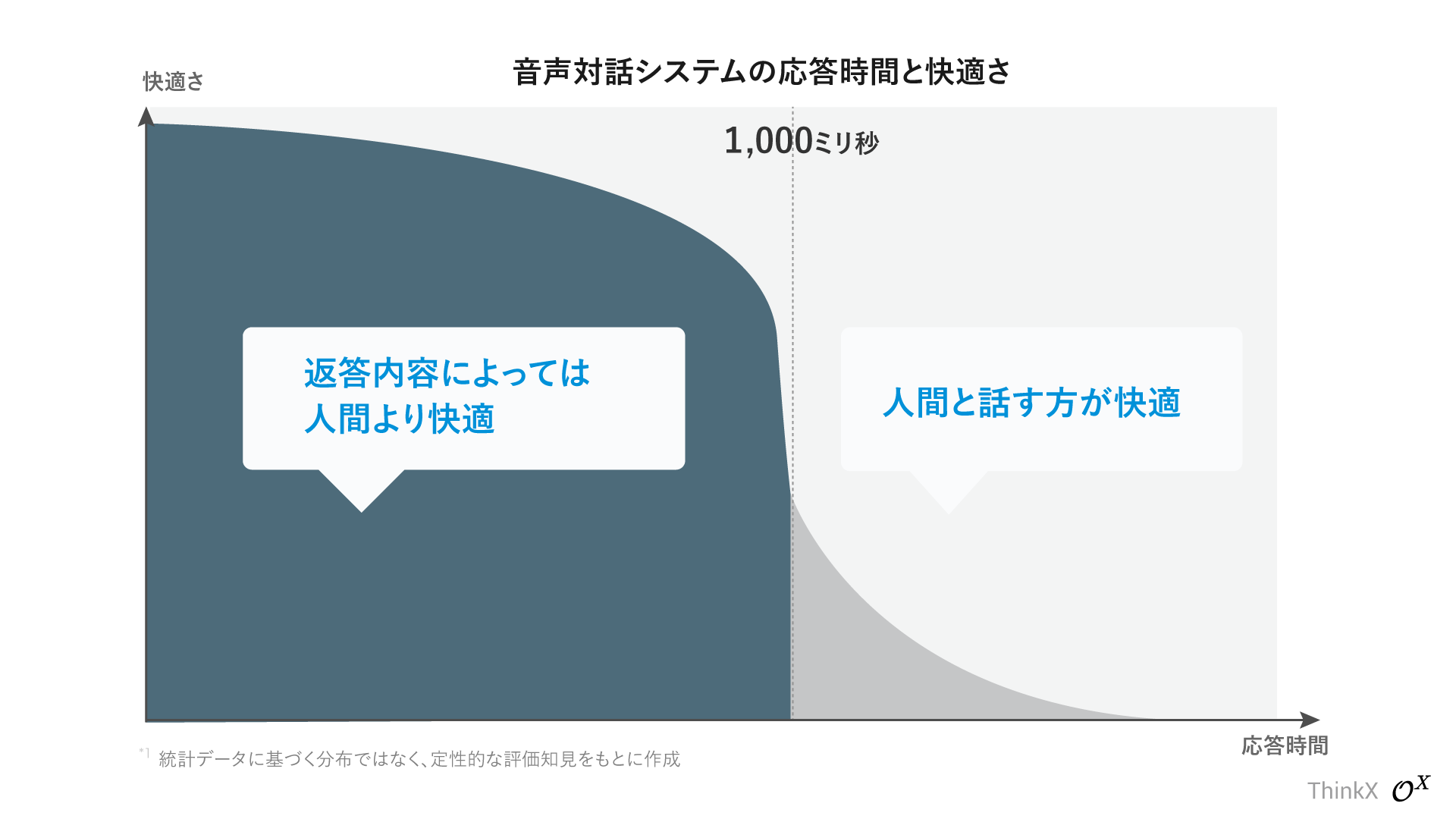
このテクニックの問題点は、数字上は応答速度1秒未満を達成するものの、本題を話し始めるまでに都度1秒~2秒かかるため、特に会話を続けるほどストレスを感じます。
Quantz ® Voice-AI OSはこのテクニックを用いず、即座に本題(実質応答)を800msで返す、外部APIを一切用いないLLMベースリアルタイムマルチモーダルシステムです。
"実質応答速度"で1秒の壁を超える
Quantz® Voice-AI OSは67万行の独自のコードベースからなる、”真に快適な対話の実現”のために最適化されたリアルタイムマルチモーダルAIシステムです(4件の特許技術を含む。うち2件は出願中)。
unix-socketベースの独自のバイト転送プロトコルにより、TCP/IP通信のオーバーヘッドを削減し、大量のデータ転送を1台のサーバーで完結する、NLP(自然言語処理)と音声処理パイプラインの超並列実装を特徴としています。
Quantz ® Voice-AI OSはThinkXが管理し、高セキュリティ要件を満たすハウジングスペースに格納された専用のGPUスーパーコンピューター上で動作します。
 GPUクラスター ThinkX Supercom3
GPUクラスター ThinkX Supercom3
67万行の独自コードベース、自社管理ハイパフォーマンスGPUコンピュータークラスター上で実行される、対話の"真の快適さ"に最適化された音声AI OS
Quantz ® Voice-AI OSは高い安全性要件を満たしたデータセンター内の物理サーバー上に構築され、ChatGPT APIやEleven Labs API等に代表される外部のAPIを一切使用しません。(オープンソースLLM Meta Llama3を微調整したモデルを、独自に実装したLLM Parallel Inference Adapterによる100~並列/GPU [2500トークン~/秒] 推論で実行)
そのため、システムユーザーにとって重要な、会話情報を外部企業に露出することがなく、最高レベルのプライバシー保護とセキュリティを実現します。
外部APIを一切使わず会話データが外出しない、最高レベルのデータセキュリティとプライバシー
外部APIを使用せず専用物理サーバー内で実行され、最高レベルのプライバシーとセキュリティ水準を実現するQuantz ® Voice-AI OSは「考えるスピードで答えが届く素早さ」と「一を聞いて十を知る賢さ」を兼ね備えます。
わずかな問いから文脈を理解し、要領よく答える最先端LLMの賢さを備えながら、30語を超える複雑な長文も800msの応答速度で遅延なくシームレスに発話します。
Quantz ® Voice-AI OSは潜在的なカスタマイズの柔軟性と高いプライバシー水準、そして実質応答の高速性による「真の快適さ」の最適なバランスを実現した音声対話エンジンです。
モジュール化された音声言語モデル。パイプラインを自由にカスタマイズ可能できる潜在的な拡張性
音声言語処理が単一の大規模言語モデルで実現されるモデル統合型のマルチモーダルAIと異なり、各モデルやプロセスが分離されているために、応答内容の途中監視や発話音声の切り替えといったパイプライン上のカスタマイズが柔軟に実現でき、潜在的な拡張性を維持しながら高い性能を実現しています。