<<
アドバイザーインタビュー: 誰もが使える超高速計算プラットフォームへ──ThinkXと東北大学が描く、AIとFPGAで切り拓くスーパーコンピューティング 張山昌論教授インタビュー
2025年2月19日
張山昌論 東北大学情報科学研究科知能集積学分野教授
今回、スーパーコンピューティングのための集積回路の一種であるFPGA(Field Programmable Gate Array)半導体の応用研究の第一人者であり、ThinkXの顧問を務めていただいている、東北大学知能集積学分野 張山教授にお話しを伺いました。


 張山 昌論(はりやま・まさのり)
張山 昌論(はりやま・まさのり)
博士(情報科学)。東北大学情報科学研究科知能集積学分野教授。FPGA(Field-Programmable Gate Arrays)を用いた応用特化型スーパーコンピューティングの国内第一人者。
大塚一輝(以下大塚)
本日は、ThinkXのプロジェクト「先端研究におけるリアルタイム・ビッグデータ解析のための動的アクセラレータ*1・システム」、わかりやすく言えば、"AI+専用半導体によるスーパーコンピュータ "のコラボレーターで、アドバイザーの東北大学の張山教授にお話しを伺います。
このプロジェクトは、高等研究のためのコンピューティング・プラットフォームであるVNマシン・クラウドの重要な機能として開発を進めています。
その目的は、複雑なデータ処理を民主化すること。果てしなく続く巨大望遠鏡の画像ストリーム(テラバイト級の星のデータを想像してみてください)の処理、量子化学、DNA配列決定のためのリアルタイム分析といったタスクを対象として、
現在は、専門家がカスタムメイドでこれらのソリューションを構築していますが、私たちの目標は、その扉を大きく開くことです。コンピューティングのノウハウを持たない研究者でも、半年かかる計算を3日で終わらせたり、電気代を半分に減らしたりすることを想像してみてください。
特に、気候モデリングや持続可能なエネルギーのような、大規模で横断的な課題に、このソリューションが価値をもつと私たちは考えています。
まず始めに、張山教授のご専門分野と最近のプロジェクトについてお聞かせください。
このプロジェクトは、高等研究のためのコンピューティング・プラットフォームであるVNマシン・クラウドの重要な機能として開発を進めています。
その目的は、複雑なデータ処理を民主化すること。果てしなく続く巨大望遠鏡の画像ストリーム(テラバイト級の星のデータを想像してみてください)の処理、量子化学、DNA配列決定のためのリアルタイム分析といったタスクを対象として、
現在は、専門家がカスタムメイドでこれらのソリューションを構築していますが、私たちの目標は、その扉を大きく開くことです。コンピューティングのノウハウを持たない研究者でも、半年かかる計算を3日で終わらせたり、電気代を半分に減らしたりすることを想像してみてください。
特に、気候モデリングや持続可能なエネルギーのような、大規模で横断的な課題に、このソリューションが価値をもつと私たちは考えています。
まず始めに、張山教授のご専門分野と最近のプロジェクトについてお聞かせください。
張山昌論教授(以下、張山)
私の専門はFPGAを用いた応用特化型スーパーコンピュータです。FPGAとは,Field-Programmable Gate Arraysの略です。これは半導体の一種で、チップを作った後でも、プログラムで回線や演算機の機能などを切り替えることによって、再プログラムが可能です。このような柔軟性により、例えば、特定のプロセスのスピードアップや電力使用量の削減などが必要なときに利用されます。また,FPGAではプログラムを変えることにより,様々な応用に対応できるため,1種類のチップを大量に生産することができ,チップの製造コストを大幅に低減できます。
我々の開発事例としては,量子アニーリングのためのソルバーですとか、ゲート型量子コンピューターのシミュレーション、自然言語処理,DNAシーケンサーなどがあります。
このようなメリットがあるFPGAですが,汎用のCPUやGPUとは異なり,応用処理に最適な回路を設計することは必ずしも容易ではありません。
我々の開発事例としては,量子アニーリングのためのソルバーですとか、ゲート型量子コンピューターのシミュレーション、自然言語処理,DNAシーケンサーなどがあります。
このようなメリットがあるFPGAですが,汎用のCPUやGPUとは異なり,応用処理に最適な回路を設計することは必ずしも容易ではありません。
H.266符号化・復号化アルゴリズムを大きな動画にリアルタイム処理したもの。(画像提供: 張山研究室)
大塚
FPGAの技術はかなり進歩しましたよね。ザイリンクスは2012年に買収され、アルテラは2022年に買収されました。私たちのアプローチは、FPGAと大規模言語モデル、つまりAIを組み合わせて、計算の定型パターンを見つけることです。OpenCLやC++のような詳細な言語ですべてを記述する代わりに、私たちはより高レベルの言語を構築します。このアイデアは、システムが正しい計算の適用方法を自ら見つけ出すように、プロセスを自動化することです。それがFPGAでどのように機能するか、詳しく教えてください。
張山
FPGAでの計算の最適化といえば、空間的並列とパイプラインという2つの大きなパターンに集約されます。空間的並列とは、複数のワーカーが同じタスクを並行して行うようなもので、複数のユニットが異なるデータに対して同じタスクを同時に行う処理です。一方、パイプライン処理は,工場の組み立てラインのようなもので、あるワーカーが結果を次のワーカーに渡し、それぞれが異なるタスクを行うことで、異なるタスクが並列に実行されます。実際には、この2つを組み合わせ有益なアーキテクチャパターンを作ります。例えば、パイプラインの,あるステージで空間並列を使用する場合もあるし、空間的並列処理,パイプライン同士をネストさせるかもしれない。あるジョブに最適な並列処理のパターンを組み合わせを見つけ出すのがポイントになってきます。
実際の設計では,全体の処理をタスクに分割し,各タスクがCPU、GPU、FPGAのどれに適しているかを判断する必要があります。そのために,私たちは、各タスクが、どのような並列性を持っていて,どれだけ並列化できるか,あるステップがどれだけ他のステップに依存しているかなどを分析します。これまでの経験から,タスクの処理のパターンは,いくつかに分類されることが分かっています。このパターンに基づくアーキテクチャのテンプレート(青写真のようなもの)から始めて、そこから微調整していきます。
実際の設計では,全体の処理をタスクに分割し,各タスクがCPU、GPU、FPGAのどれに適しているかを判断する必要があります。そのために,私たちは、各タスクが、どのような並列性を持っていて,どれだけ並列化できるか,あるステップがどれだけ他のステップに依存しているかなどを分析します。これまでの経験から,タスクの処理のパターンは,いくつかに分類されることが分かっています。このパターンに基づくアーキテクチャのテンプレート(青写真のようなもの)から始めて、そこから微調整していきます。
チップ同士を連結させることで大規模データにスケールアップできる。(画像提供: 張山研究室)
大塚
つまり、ある程度パターンが標準化されたとしても、特定のタスクのために微調整する必要があるということですね?そのチューニングをスムーズに行えるようになるまで、どのような点がネックになるでしょうか?
張山
一度にどれだけのデータが入ってくるのか、どれだけのスピードで処理する必要があるのかといった制約条件にもよります。入ってくるデータを見て、"このようなワークロードなら、このように最適化する "と判断するようにシステムをプログラミングする。データフローが重ければパイプラインの深さを深くし、広範囲であれば空間ユニットを増やす。このようなロジックを十分に組み込めば、システムは自動的に適応し、調整することができると考えています。C言語のプログラムからFPGA回路の合成には,10時間ぐらいかかる場合もあります。このコンパイル時間を減らすためにも、アルテラジャパンの方々とも連携し、部分再構成をOneAPI*2に盛り込むなど、技術提供も含めてコラボレートしていくことでFPGA設計を効率化できるはずです。
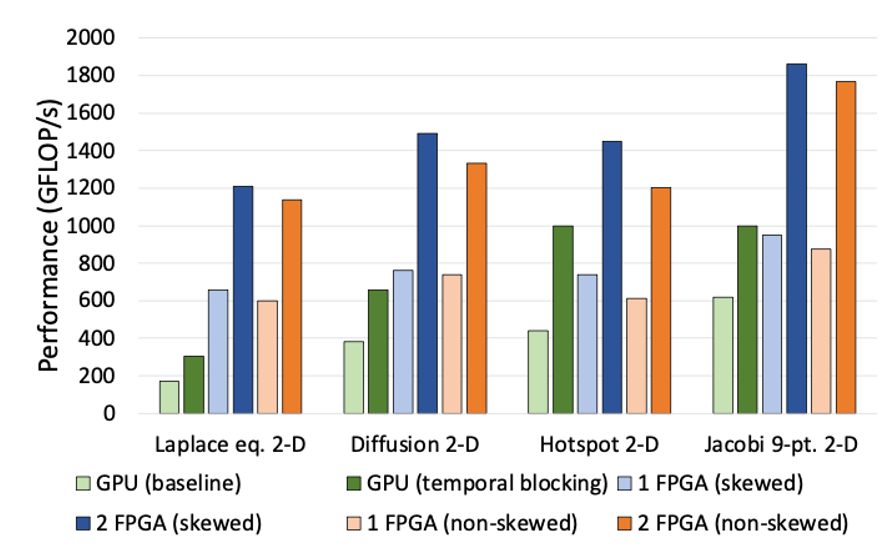
GPUとの比較ベンチマーク。複数のFPGAを接続することで線形にパフォーマンスが向上し、たった2枚でもGPUを大きく超える処理能力に達している。(画像提供: 張山研究室)
大塚
もうひとつ特筆すべきだと思うのは、FPGAを連結できるスケーラビリティです。複数のチップをつなげば、1つの巨大な回路のように機能しますよね。私たちのクラウド・セットアップでは、コンピューティング・インスタンスを提供し、ユーザーは複数のユニットでこの機能を利用することができることを意味します。どのような展開が予想されますか?
張山
FPGAの強みのひとつは、スケールアップが非常に簡単なことです。ケーブルでつないでセットアップを調整するだけです。これは実はあまり知られていません。例えば、巨大なグラフ構造や、気候モデル用の1万×1万グリッドの巨大な行列計算、量子化学のような1兆分の1から兆分の1までの数字を扱う4倍精度の計算が必要な場合。CPUやGPUは、問題が大きくなるにつれて速度が低下します。しかしFPGAでは、割と簡単に、複数個をケーブルで接続すれば、1つの巨大なチップのように動作します。ほとんどシームレスで、規模が大きくなっても速度が落ちることはない。科学計算や特殊なタスクにとっては、これは画期的なことです。
大塚
本当にそうです。張山先生、貴重なお話をありがとうございました。今後もよろしくお願いします。
*1 動的アクセラレータ: 計算の内容に応じてプロセッサの構成を動的に切り替え、処理速度や電力効率を高める技術
*2 OneAPI: Intelが開発するハードウェアプログラム用のオープンな言語。
*2 OneAPI: Intelが開発するハードウェアプログラム用のオープンな言語。
張山 昌論(はりやま・まさのり)博士(情報科学)。東北大学情報科学研究科知能集積学分野教授。FPGA(Field-Programmable Gate Arrays)を用いた応用特化型スーパーコンピューティングの国内第一人者。