Un algorithme de personnalisation qui analyse les intérêts potentiels des utilisateurs à partir de descriptions textuelles.
En analysant les textes rédigés par les utilisateurs avec un minimum de ressources de calcul, identifie leurs préférences qualitatives (avant-gardistes, pop, luxueuses, modernes, etc.), corrige les écarts dans les recommandations et réponses, et offre une personnalisation précise pour des goûts variés.
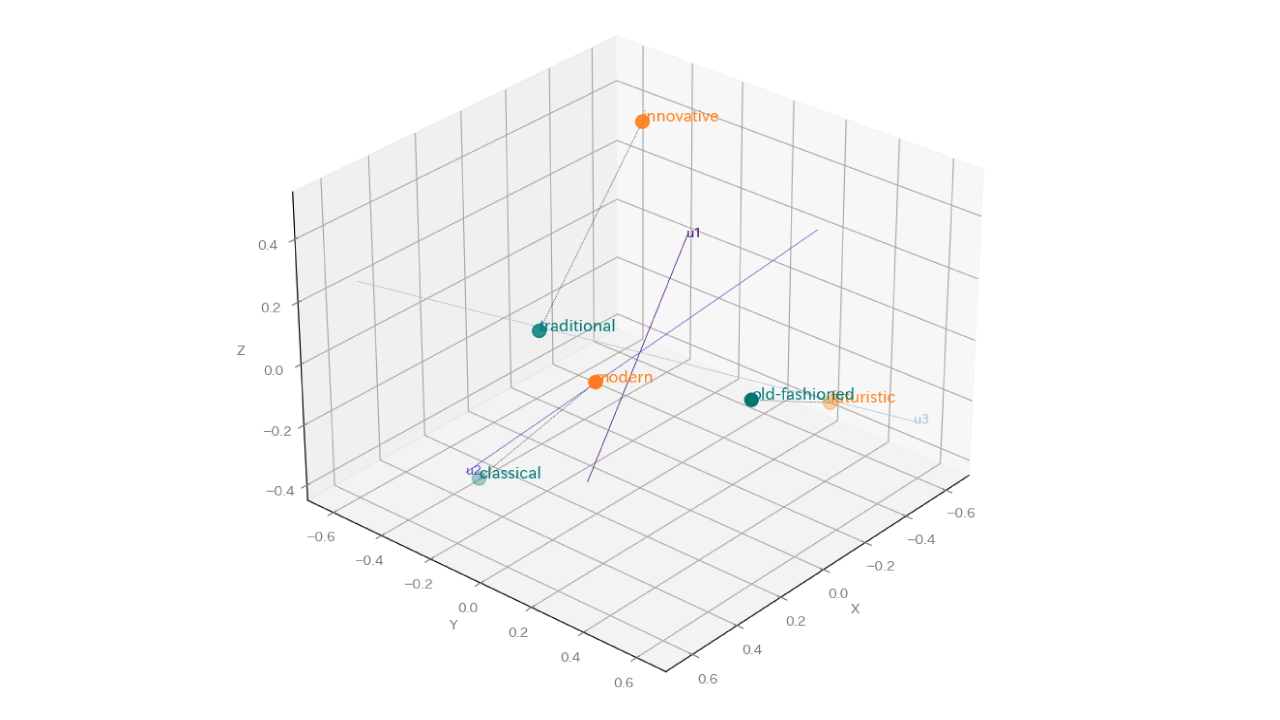
En s'appuyant sur les propriétés géométriques d’un hyperespace linguistique et notre algorithme propriétaire de machine learning, nous analysons les préférences et les traits de personnalité décrits dans le texte d’un utilisateur, sans exiger l’accumulation de données comportementales. Notre algorithme de superplan sémantique unique, situé dans l’espace d’embedding lexical et basé sur des groupes conceptuels définis par des antonymes, fonctionne avec un temps de calcul minimal. De cette façon, nous déduisons les inclinaisons difficiles à discerner chez les utilisateurs disposant de peu d’historique ou d’informations initiales, améliorant ainsi les capacités de recommandation, de proposition de produits et de personnalisation du service. (Brevet obtenu : numéro 7393772)
Il résout également le problème de cold start dû à un manque de données comportementales initiales, un défi de longue date dans les systèmes de recommandation classiques.
Dans les algorithmes de recommandation classiques, ils ne fonctionnent pas tant qu’un certain volume de données comportementales n’est pas accumulé, ce qui les rend impuissants pour les nouveaux utilisateurs, pourtant cruciaux. Ce problème est appelé le problème de cold start (les systèmes ne fonctionnent pas sans données accumulées), un défaut majeur des algorithmes traditionnels. À l’inverse, l’algorithme LSH n’a pas besoin d’accumuler des données comportementales : il lui suffit d’un bref texte descriptif de l’utilisateur pour déduire immédiatement ses préférences. Ainsi, il peut fournir une personnalisation immédiate même aux nouveaux utilisateurs dès leurs premières interactions.
Dans cette ère post-médias de masse, il peut répondre avec précision à la diversité et à la segmentation croissantes des goûts et préférences du public moderne.
Les algorithmes de recommandation fondés sur des bases de données comportementales garantissent finalement leur précision en proposant systématiquement des produits populaires auprès de la majorité, ce qui a suscité des critiques quant à leur incapacité à répondre à une diversité de goûts et de préférences.
Dans le contexte actuel où les médias de masse disparaissent peu à peu, il est nécessaire de disposer d’algorithmes de personnalisation capables de s’adapter à des centres d’intérêt de plus en plus variés.
Grâce à sa géométrie hyper-spatiale linguistique unique, l’algorithme LSH peut définir et identifier librement des vecteurs d’intérêts de niche, par exemple pour ceux qui aiment les choses simples, les choses insolites, les choses voyantes, les choses pragmatiques ou encore les objets des années 60.