El sistema de IA multimodal en tiempo real más rápido de la industria con 'respuesta real' ofrece 'verdadera comodidad' y 'privacidad completa'.
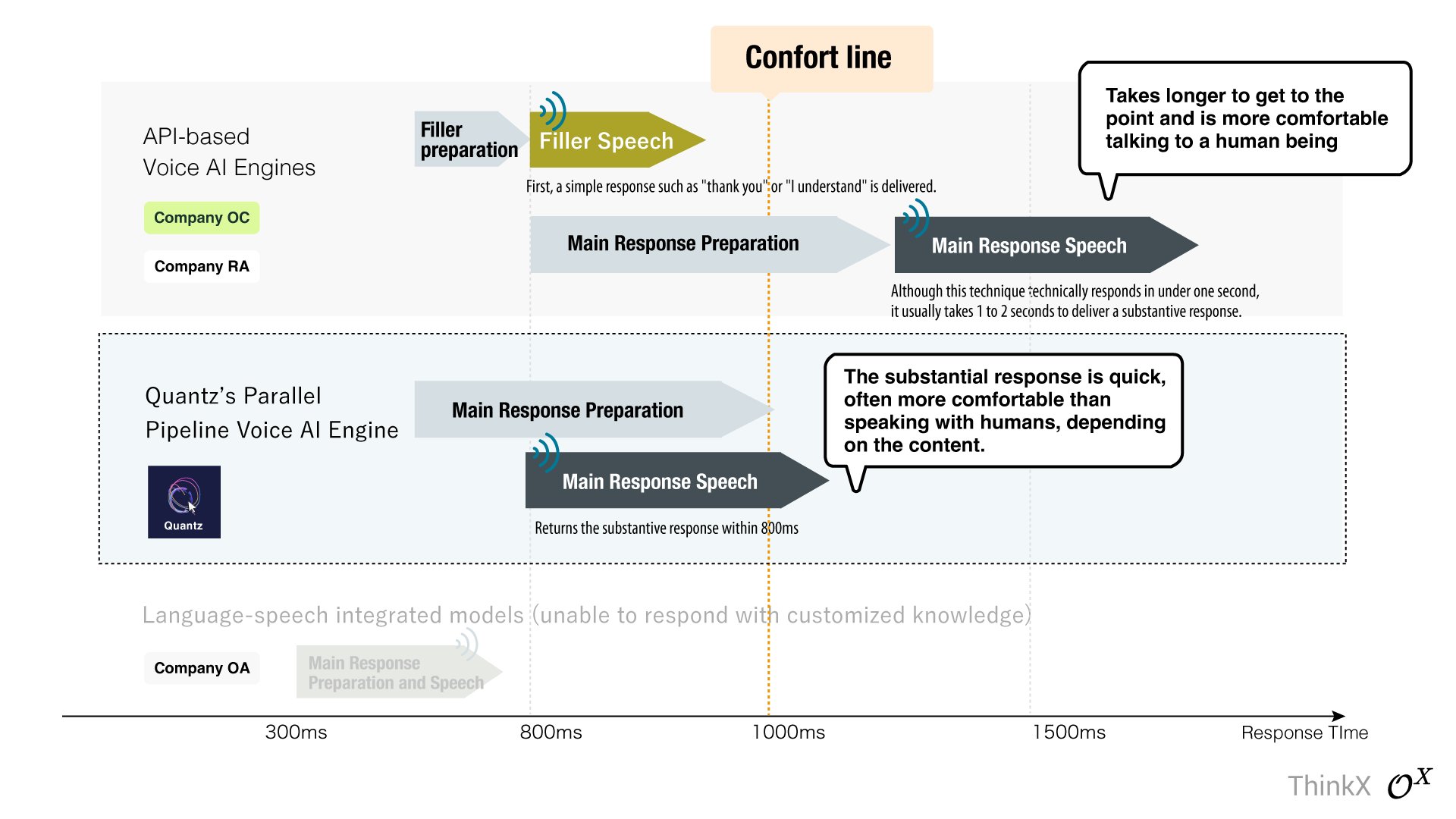
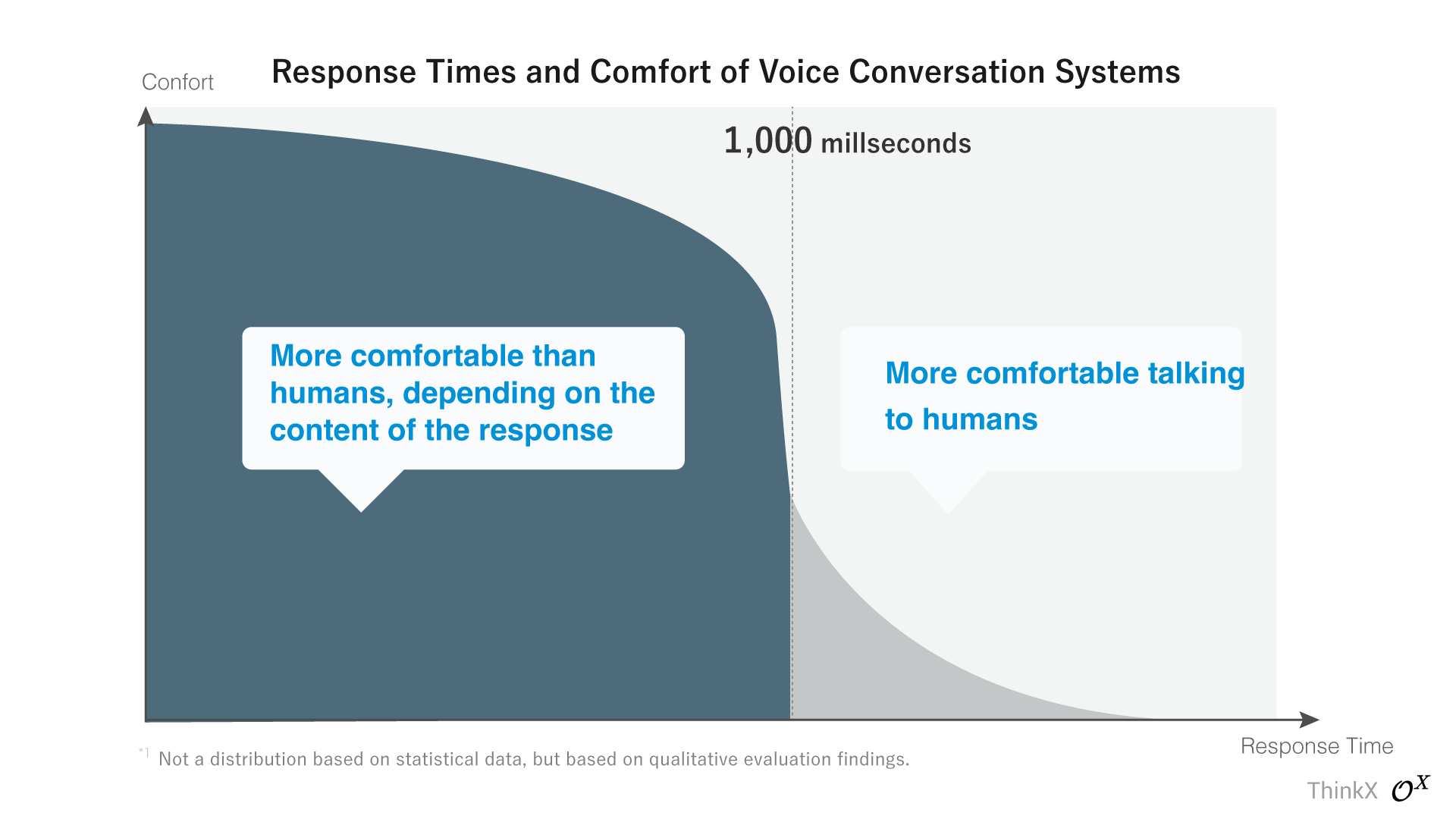
Quantz ® Voice-AI OS entrega inmediatamente la respuesta sustantiva, logrando un tiempo de respuesta de solo 800 ms, evitando la técnica de relleno común que depende de respuestas simples como 'gracias'.
Muchos motores de IA de voz típicos basados en API luchan por superar la 'barrera de un segundo' y recurren a la 'técnica de relleno'. Esto implica emitir una respuesta preliminar como 'gracias' o 'entiendo' mientras se prepara la respuesta principal. Aunque este enfoque puede lograr un tiempo de respuesta numérico de menos de un segundo, se necesitan de 1 a 2 segundos antes de abordar el tema principal, lo que puede ser frustrante durante interacciones más largas.
Quantz ® Voice-AI OS, el primer motor de IA de voz basado en LLM del mundo, evita esta técnica, entregando el tema principal: la respuesta real, dentro de los 800 ms.
Supera la barrera de un segundo en tiempo de respuesta real
Quantz® Voice-AI OS está diseñado para proporcionar 'verdadera comodidad', basado en una base de código propia de 670,000 líneas que incluye 4 tecnologías patentadas, con 2 patentes pendientes. Caracteriza una implementación masivamente paralela de los procesos de NLP (procesamiento de lenguaje natural) y de procesamiento de voz, utilizando un protocolo único de transferencia de bytes basado en unix-socket que reduce la sobrecarga de la comunicación TCP/IP y permite completar grandes transferencias de datos en un solo servidor. El sistema es operado en supercomputadoras GPU dedicadas administradas por ThinkX, asegurando un rendimiento robusto en un espacio altamente seguro.
Nuestro Clúster GPU ThinkX Supercom3
OS de IA de voz optimizado para 'verdadera comodidad', funcionando en un clúster de computadoras GPU de alto rendimiento gestionado internamente, con una base de código propietaria de 670,000 líneas
Quantz ® Voice-AI OS está construido en servidores físicos en centros de datos con altos requisitos de seguridad y no utiliza ninguna API externa como ChatGPT API, Eleven Labs API, etc. (Los modelos ajustados del LLM Meta Llama3 de código abierto se ejecutan con 100~ paralelo/GPU [2500 tokens~/seg] de inferencia mediante una implementación propietaria del LLM Parallel Inference Adapter).
Esto garantiza el más alto nivel de protección de la privacidad y seguridad para los usuarios del sistema al no exponer información crítica de la conversación a empresas externas.
El más alto nivel de seguridad de datos y privacidad—sin API externas, sin datos conversacionales salientes
A diferencia de los sistemas multimodales integrados que dependen de un único LLM para el procesamiento de voz y lenguaje, nuestra arquitectura separa cada modelo y proceso. Esta separación permite una personalización flexible del pipeline, incluyendo monitoreo durante la respuesta y cambio entre expresiones, todo mientras se mantiene la potencial escalabilidad y se logra un alto rendimiento.
Modelos de lenguaje y habla modularizados: pipeline escalable y personalizable
Quantz ® Voice-AI OS opera en servidores físicos dedicados, garantizando una seguridad de datos incomparable al eliminar la dependencia de las API externas. Esta configuración garantiza que no se transmitan datos conversacionales externamente, manteniendo los estándares de privacidad más estrictos.
"Donde las respuestas llegan a la velocidad del pensamiento" - Quantz cumple esta promesa a través de la inteligencia del LLM de última generación. Habla menos y resuelve más con Quantz; entiende incluso las consultas más concisas y proporciona respuestas precisas y directas. Maneja sin esfuerzo oraciones largas y complejas de más de 30 palabras y proporciona respuestas en un impresionante 800ms.
Quantz ® Voice-AI OS logra el equilibrio óptimo entre la flexibilidad de personalización, los estrictos estándares de privacidad y el 'verdadero confort', proporcionando respuestas rápidas y reales para mejorar la experiencia del usuario.
 Nuestro Clúster GPU ThinkX Supercom3
Nuestro Clúster GPU ThinkX Supercom3
