<<
Entrevista con el asesor: Hacia una plataforma de cómputo ultrarrápida para todos—ThinkX y la Universidad de Tohoku imaginan la supercomputación con IA y FPGA: Entrevista con el profesor Masanori Hariyama
19 de febrero de 2025
Masanori Hariyama, Profesor de Sistemas Integrados Inteligentes, Escuela de Posgrado de Ciencias de la Información, Universidad de Tohoku
En esta ocasión, hablamos con el profesor Masanori Hariyama, del campo de Sistemas Integrados Inteligentes de la Universidad de Tohoku, un experto líder en la investigación aplicada de semiconductores FPGA (Field Programmable Gate Array), un tipo de circuito integrado para supercomputación, y asesor de ThinkX.


 Masanori Hariyama
Masanori Hariyama
Doctor en Ciencias de la Información. Profesor en la Escuela de Posgrado de Ciencias de la Información, Sistemas Integrados Inteligentes, Universidad de Tohoku. Experto líder en Japón en supercomputación específica para aplicaciones utilizando FPGA (Field-Programmable Gate Arrays).
Kazuki Otsuka (en adelante Otsuka)
Hoy hablamos con el profesor Masanori Hariyama de la Universidad de Tohoku, colaborador y asesor del proyecto de ThinkX 'Sistema de Acelerador Dinámico*1 para el Análisis en Tiempo Real de Big Data en Investigación Avanzada'—o, en términos más simples, 'una supercomputadora impulsada por IA y semiconductores especializados'.
Este proyecto se está desarrollando como una función clave de VN Machine Cloud, una plataforma de cómputo para investigación avanzada. El objetivo es democratizar el procesamiento de datos complejos. Piense en tareas como manejar flujos interminables de imágenes de telescopios gigantes (imagine terabytes de datos estelares), análisis en tiempo real para química cuántica y secuenciación de ADN. Actualmente, los expertos construyen estas soluciones a medida, pero nuestro objetivo es abrir esa puerta de par en par. Imagine investigadores sin experiencia en cómputo terminando cálculos que toman seis meses en solo tres días o reduciendo los costos de electricidad a la mitad. Creemos que esta solución tiene un valor especial para desafíos interdisciplinarios y a gran escala como el modelado climático o la energía sostenible.
Para empezar, profesor Hariyama, ¿podría contarnos sobre su especialidad y proyectos recientes?
Este proyecto se está desarrollando como una función clave de VN Machine Cloud, una plataforma de cómputo para investigación avanzada. El objetivo es democratizar el procesamiento de datos complejos. Piense en tareas como manejar flujos interminables de imágenes de telescopios gigantes (imagine terabytes de datos estelares), análisis en tiempo real para química cuántica y secuenciación de ADN. Actualmente, los expertos construyen estas soluciones a medida, pero nuestro objetivo es abrir esa puerta de par en par. Imagine investigadores sin experiencia en cómputo terminando cálculos que toman seis meses en solo tres días o reduciendo los costos de electricidad a la mitad. Creemos que esta solución tiene un valor especial para desafíos interdisciplinarios y a gran escala como el modelado climático o la energía sostenible.
Para empezar, profesor Hariyama, ¿podría contarnos sobre su especialidad y proyectos recientes?
Profesor Masanori Hariyama (en adelante Hariyama)
Mi especialidad son las supercomputadoras específicas para aplicaciones utilizando FPGAs. FPGA significa Field-Programmable Gate Arrays. Es un tipo de semiconductor que se puede reprogramar después de fabricado al alterar sus circuitos o funciones computacionales mediante programación. Esta flexibilidad lo hace útil cuando, por ejemplo, necesitas acelerar procesos específicos o reducir el consumo de energía. Además, al cambiar el programa, los FPGAs pueden adaptarse a diversas aplicaciones, permitiendo la producción en masa de un solo tipo de chip, reduciendo significativamente los costos de fabricación.
Ejemplos de nuestros desarrollos incluyen solucionadores para recocido cuántico, simulaciones de computadoras cuánticas de puertas, procesamiento de lenguaje natural y secuenciadores de ADN.
Aunque los FPGAs ofrecen estas ventajas, diseñar circuitos optimizados para aplicaciones específicas no siempre es fácil, a diferencia de las CPUs o GPUs de propósito general.
Ejemplos de nuestros desarrollos incluyen solucionadores para recocido cuántico, simulaciones de computadoras cuánticas de puertas, procesamiento de lenguaje natural y secuenciadores de ADN.
Aunque los FPGAs ofrecen estas ventajas, diseñar circuitos optimizados para aplicaciones específicas no siempre es fácil, a diferencia de las CPUs o GPUs de propósito general.
Procesamiento en tiempo real del algoritmo de codificación/decodificación H.266 en archivos de video grandes. (Imagen proporcionada por: Laboratorio Hariyama)
Otsuka
La tecnología FPGA ha avanzado mucho, ¿verdad? Xilinx fue adquirida en 2012 y Altera en 2022. Nuestro enfoque combina FPGAs con modelos de lenguaje a gran escala—es decir, IA—para identificar patrones computacionales estandarizados. En lugar de escribir todo en lenguajes detallados como OpenCL o C++, estamos construyendo un lenguaje de nivel superior. La idea es automatizar el proceso para que el sistema descubra por sí mismo la manera correcta de aplicar los cálculos. ¿Podría explicar en detalle cómo funciona eso con los FPGAs?
Hariyama
La optimización en la computación con FPGA se reduce a dos patrones principales: paralelismo espacial y tuberías (pipelining). El paralelismo espacial es como tener varios trabajadores haciendo la misma tarea al mismo tiempo—varias unidades realizan la misma tarea en diferentes datos simultáneamente. El pipelining, por otro lado, es como una línea de ensamblaje en una fábrica: un trabajador pasa los resultados al siguiente, cada uno manejando una tarea diferente, permitiendo que varias tareas se ejecuten en paralelo. En la práctica, combinamos estos para crear patrones arquitectónicos beneficiosos. Por ejemplo, podríamos usar paralelismo espacial dentro de una etapa de la tubería o anidar tuberías dentro del paralelismo espacial. La clave está en encontrar la combinación óptima de estos patrones para un trabajo dado.
En el diseño real, dividimos todo el proceso en tareas y decidimos cuáles son más adecuadas para CPUs, GPUs o FPGAs. Para esto, analizamos el paralelismo de cada tarea, cuánto se puede paralelizar y cuánto depende un paso de otro. Por experiencia, hemos descubierto que los patrones de procesamiento de tareas se dividen en unas pocas categorías. Comenzamos con plantillas de arquitectura basadas en estos patrones—como planos—y ajustamos desde ahí.
En el diseño real, dividimos todo el proceso en tareas y decidimos cuáles son más adecuadas para CPUs, GPUs o FPGAs. Para esto, analizamos el paralelismo de cada tarea, cuánto se puede paralelizar y cuánto depende un paso de otro. Por experiencia, hemos descubierto que los patrones de procesamiento de tareas se dividen en unas pocas categorías. Comenzamos con plantillas de arquitectura basadas en estos patrones—como planos—y ajustamos desde ahí.
Escalado a grandes conjuntos de datos mediante la conexión de chips. (Imagen proporcionada por: Laboratorio Hariyama)
Otsuka
Entonces, aunque los patrones estén algo estandarizados, aún se necesita ajustar para tareas específicas, ¿correcto? ¿Cuáles son los cuellos de botella para hacer ese ajuste más fluido?
Hariyama
Depende de restricciones como cuántos datos entran a la vez y qué tan rápido necesitan procesarse. Programamos el sistema para que mire los datos entrantes y decida, 'Para esta carga de trabajo, optimiza de esta manera'. Si el flujo de datos es pesado, profundizamos la tubería; si es amplio, añadimos más unidades espaciales. Con suficiente lógica incorporada, el sistema puede adaptarse y ajustarse automáticamente. Sintetizar circuitos FPGA desde código C puede tomar unas 10 horas en algunos casos. Para reducir este tiempo de compilación, colaboramos con Altera Japón, integrando reconfiguración parcial en OneAPI*2 y aportando tecnología para agilizar el diseño de FPGAs.
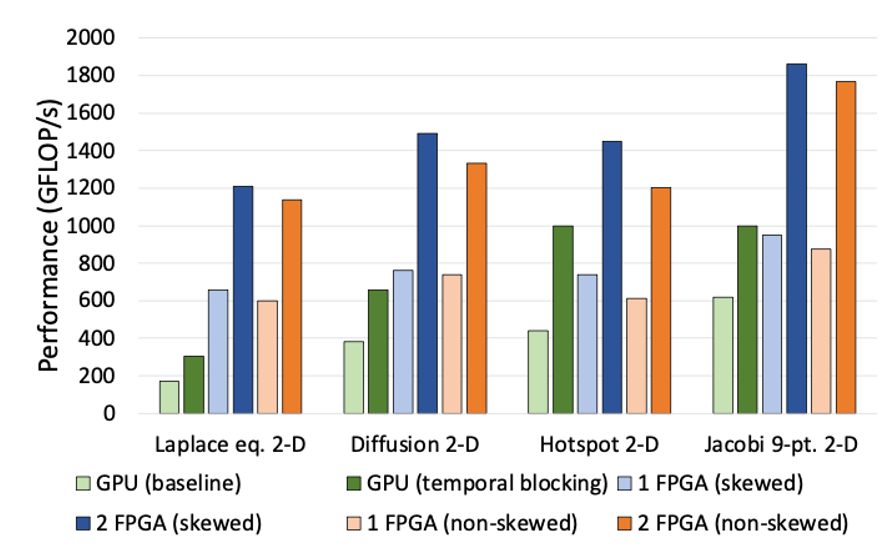
Comparación de rendimiento con GPUs. Conectar múltiples FPGAs mejora el rendimiento linealmente, superando ampliamente a las GPUs con solo dos unidades. (Imagen proporcionada por: Laboratorio Hariyama)
Otsuka
Otra cosa que creo que vale la pena destacar es la escalabilidad de conectar FPGAs. Unir varios chips los hace funcionar como un circuito gigante, ¿verdad? En nuestra configuración en la nube, esto significa que ofrecemos instancias de cómputo donde los usuarios pueden aprovechar esto en múltiples unidades. ¿Qué desarrollos prevé?
Hariyama
Una de las fortalezas de los FPGAs es lo fácil que es escalarlos—solo hay que conectarlos con cables y ajustar la configuración. Esto no es muy conocido. Por ejemplo, con estructuras de gráficos masivos, cálculos de matrices enormes para modelos climáticos (piense en cuadrículas de 10,000 x 10,000), o cómputos de precisión cuádruple para química cuántica manejando números desde billonésimas hasta billones, las CPUs y GPUs se ralentizan a medida que crece el problema. Pero con FPGAs, conectar varias unidades con cables las hace actuar como un chip gigante. Es casi sin fisuras, y la velocidad no disminuye con la escala. Para la computación científica o tareas especializadas, esto es revolucionario.
Otsuka
Totalmente de acuerdo. Profesor Hariyama, gracias por esta valiosa conversación. Esperamos seguir colaborando.
*1 Acelerador Dinámico: Tecnología que reconfigura dinámicamente las configuraciones del procesador según las necesidades de cómputo, mejorando la velocidad y la eficiencia energética.
*2 OneAPI: Un lenguaje abierto para programación de hardware desarrollado por Intel.
*2 OneAPI: Un lenguaje abierto para programación de hardware desarrollado por Intel.
Masanori HariyamaDoctor en Ciencias de la Información. Profesor en la Escuela de Posgrado de Ciencias de la Información, Sistemas Integrados Inteligentes, Universidad de Tohoku. Experto líder en Japón en supercomputación específica para aplicaciones utilizando FPGA (Field-Programmable Gate Arrays).