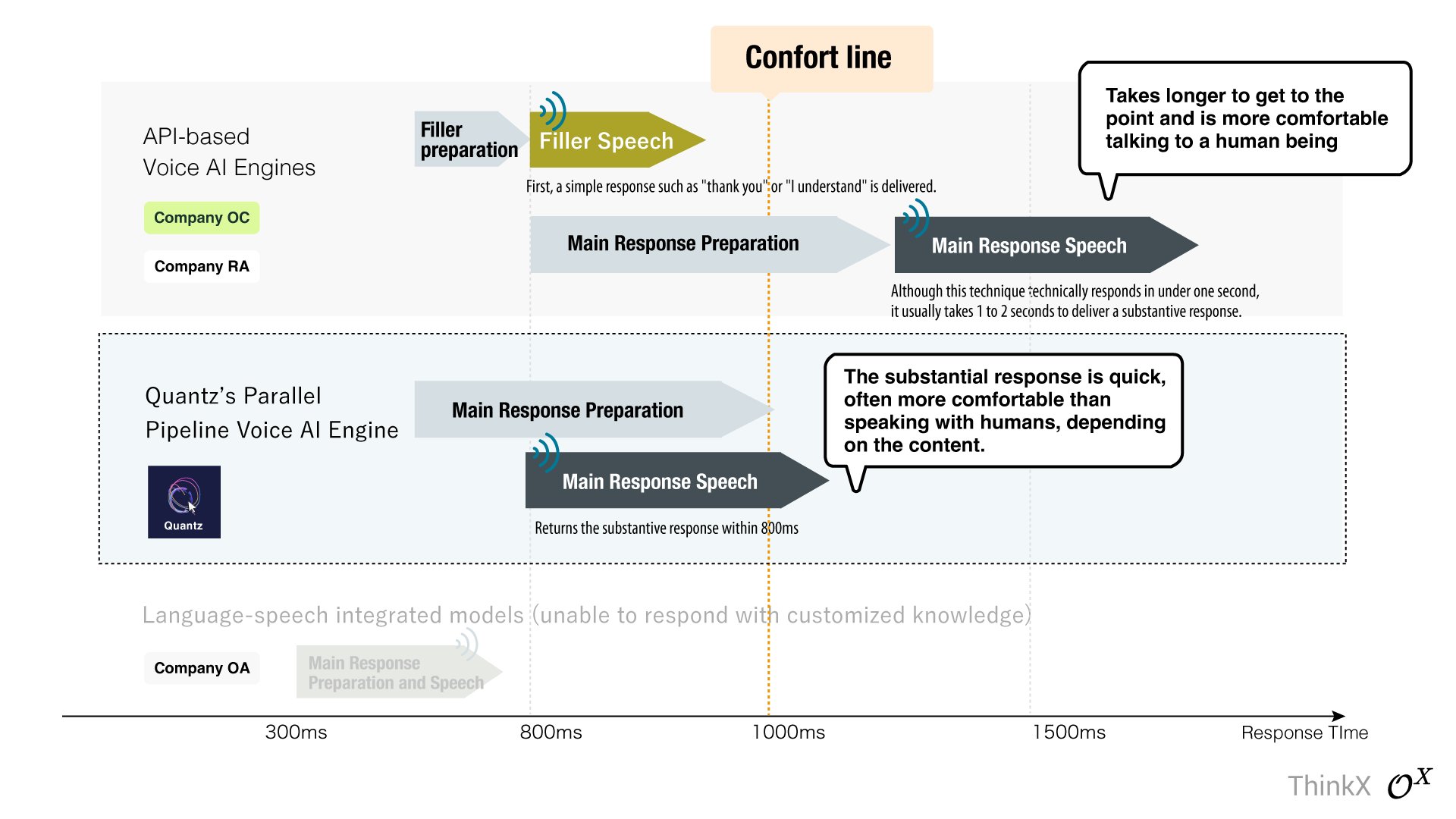
Quantz ® Voice-AI OS立即提供实质性回应,响应时间仅为800毫秒,避免了依赖于简单回应如“谢谢”的常见填充技术。
许多典型的基于API的语音AI引擎很难突破“1秒的障碍”,并使用“填充技术”。这涉及在准备主要响应时发出“谢谢”或“我明白了”等初步响应。尽管这种方法可以实现不到一秒的数字响应时间,但在解决主要问题之前需要1到2秒,这在较长的互动过程中可能会令人沮丧。
Quantz ® Voice-AI OS,世界上第一个基于LLM的语音AI引擎,避免了这种技术,在800毫秒内提供主要话题——真实响应。
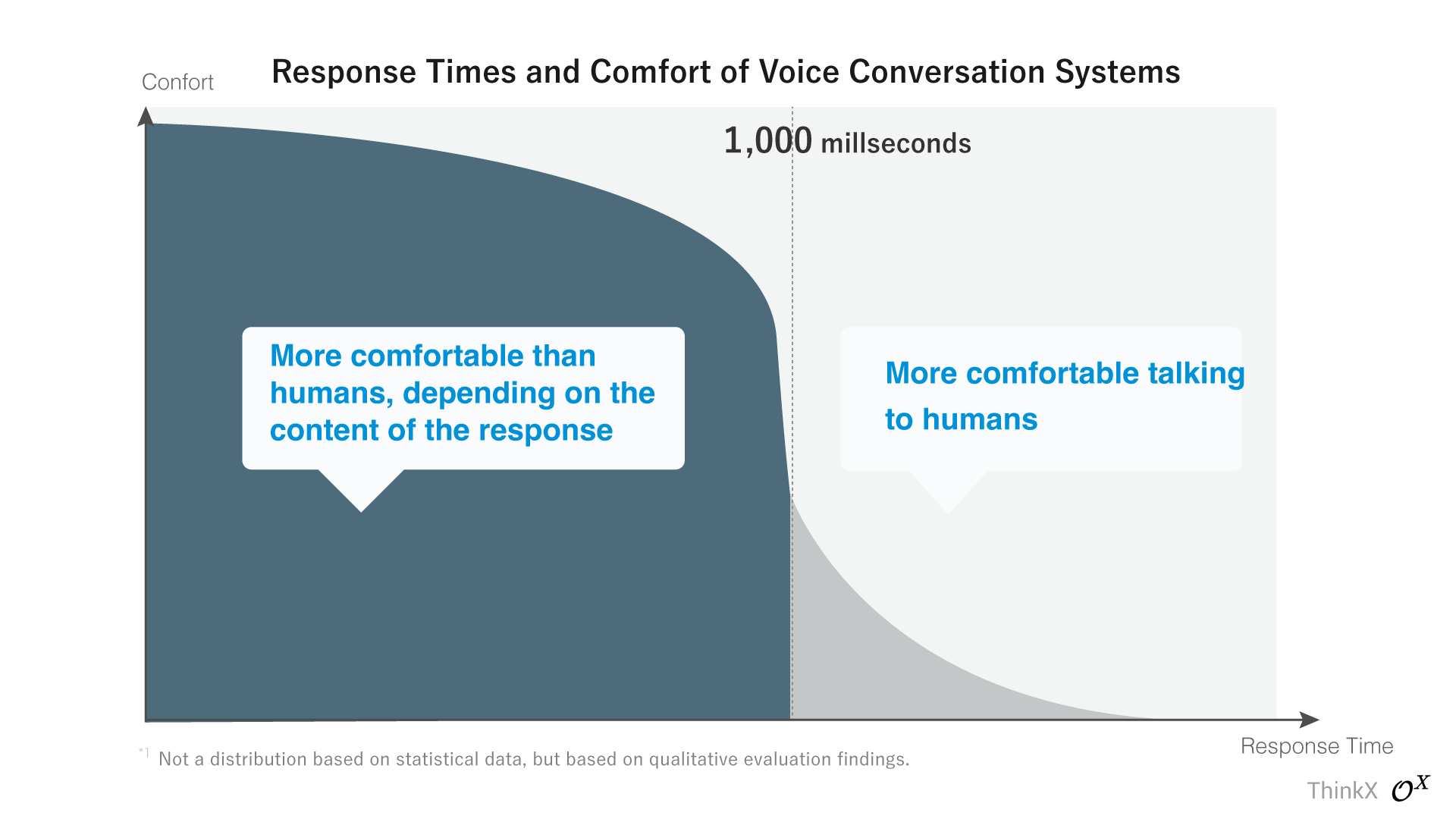
在实时响应速度中突破一秒障碍
Quantz® Voice-AI OS 是为“真正的舒适”而设计的,基于67万行独有代码库,包括4项已申请的专利技术(其中2项仍在申请中)。系统采用unix-socket基于的独特字节传输协议,显著减少了TCP/IP通信的开销,并允许在单一服务器上完成大量数据传输。这一NLP(自然语言处理)和语音处理的超并行实现,确保了高性能。Quantz® Voice-AI OS 由ThinkX管理,运行在高安全性要求的专用GPU超级计算机上。
我们的GPU集群 ThinkX Supercom3
在自家管理的高性能GPU计算机集群上运行的语音AI操作系统,优化为“真正的舒适”,具有670,000行专有代码库
Quantz ® Voice-AI OS 构建在具有高安全要求的数据中心的物理服务器上,不使用任何外部API,例如ChatGPT API、Eleven Labs API等。(从开源LLM Meta Llama3微调的模型通过LLM Parallel Inference Adapter的专有实现以100~并行/GPU [2500个令牌/秒]推断执行)。
这确保了系统用户的最高级别隐私保护和安全性,因为不会将关键的会话信息暴露给外部公司。
最高级别的数据安全性和隐私——无外部API,无外发会话数据
与依赖单一大型语言模型实现声音和语言处理的一体化多模态AI系统不同,我们的架构将各个模型和过程分离。这种分离使得管道的灵活定制成为可能,包括响应中监控和语音切换,同时保持潜在的可扩展性和高性能。
模块化语言和语音模型:可扩展且可定制的管道
Quantz ® Voice-AI OS 在专用物理服务器上运行,通过消除对外部API的依赖,确保无与伦比的数据安全性。这种设置保证不会向外部传输会话数据,从而维护最严格的隐私标准。
“答案到达思维的速度”——Quantz通过最先进的LLM的智能实现了这一承诺。使用Quantz少说多解决问题;它甚至可以理解最简洁的查询,并提供精确到位的答案。它可以毫不费力地处理超过30个单词的复杂长句,并在令人印象深刻的800毫秒内提供响应。
Quantz ® Voice-AI OS 实现了定制灵活性、严格隐私标准和“真正舒适性”之间的最佳平衡,提供快速和真实的响应以增强用户体验。
 我们的GPU集群 ThinkX Supercom3
我们的GPU集群 ThinkX Supercom3
