<<
顾问专访:迈向人人都能使用的高速计算平台——ThinkX与东北大学描绘的AI与FPGA开启的超级计算 张山昌论教授专访
2025年2月19日
张山昌论,东北大学信息科学研究科智能集成系统领域教授
这次,我们采访了东北大学智能集成系统领域的张山昌论教授,他是超级计算用集成电路FPGA(现场可编程门阵列)半导体应用研究的顶尖专家,也是ThinkX的顾问。


 张山昌论
张山昌论
信息科学博士。东北大学信息科学研究科智能集成系统领域教授。日本使用FPGA(现场可编程门阵列)进行应用专用超级计算的顶尖专家。
大塚一辉(以下简称大塚)
今天,我们将与东北大学的张山昌论教授交谈,他是ThinkX项目“用于尖端研究的实时大数据解析的动态加速器*1系统”——简单来说,“人工智能+专用半导体驱动的超级计算机”的合作者和顾问。
该项目是作为高级研究计算平台VN机器云的重要功能而开发的。其目标是使复杂的处理数据民主化。设想一下处理巨型望远镜的无限图像流(想象太字节级的星星数据)、量子化学和DNA测序的实时分析等任务。目前,专家们为这些解决方案定制开发,但我们的目标是大开方便之门。想象一下,即使是没有计算专长的研究人员,也能将需要六个月的计算在三天内完成,或者将电费减半。我们认为,这种解决方案在大规模、跨学科的挑战中,如气候建模或可持续能源,尤为有价值。
首先,张山教授能否介绍一下您的专业领域和最近的项目?
该项目是作为高级研究计算平台VN机器云的重要功能而开发的。其目标是使复杂的处理数据民主化。设想一下处理巨型望远镜的无限图像流(想象太字节级的星星数据)、量子化学和DNA测序的实时分析等任务。目前,专家们为这些解决方案定制开发,但我们的目标是大开方便之门。想象一下,即使是没有计算专长的研究人员,也能将需要六个月的计算在三天内完成,或者将电费减半。我们认为,这种解决方案在大规模、跨学科的挑战中,如气候建模或可持续能源,尤为有价值。
首先,张山教授能否介绍一下您的专业领域和最近的项目?
张山昌论教授(以下简称张山)
我的专长是使用FPGA的应用专用超级计算机。FPGA是Field-Programmable Gate Arrays的缩写。这是一种半导体,即使在制造后,也可以通过编程更改其电路或计算功能来重新编程。这种灵活性使得它在需要加速特定过程或减少功耗时非常有用。此外,通过更改程序,FPGA可以适应各种应用,从而可以大量生产单一类型的芯片,大幅降低制造成本。
我们的开发案例包括量子退火的求解器、门控量子计算机的模拟、自然语言处理和DNA测序仪等。
尽管FPGA有这些优势,但与通用的CPU或GPU不同,设计针对特定应用优化的电路并不总是容易的。
我们的开发案例包括量子退火的求解器、门控量子计算机的模拟、自然语言处理和DNA测序仪等。
尽管FPGA有这些优势,但与通用的CPU或GPU不同,设计针对特定应用优化的电路并不总是容易的。
对大型视频文件实时处理H.266编码/解码算法。(图片提供:张山研究室)
大塚
FPGA技术已经取得了很大进步,对吧?Xilinx在2012年被收购,Altera在2022年被收购。我们的方法是将FPGA与大规模语言模型(也就是AI)相结合,找到计算的标准化模式。我们不是用OpenCL或C++这样的详细语言编写一切,而是构建更高级的语言。这个想法是自动化流程,让系统自己找出正确的计算应用方法。这在FPGA上是如何运作的,能否详细说明?
张山
FPGA的计算优化可以归结为两种主要模式:空间并行和流水线。空间并行就像多个工人同时执行相同任务——多个单元同时对不同数据执行相同任务。而流水线处理就像工厂的装配线,一个工人将结果传递给下一个工人,每人执行不同任务,从而并行运行多个任务。实际上,我们将这两者结合起来,创建有益的架构模式。例如,我们可能在流水线的某个阶段使用空间并行,或者将流水线嵌套在空间并行中。关键是找到适合特定工作的并行处理模式的组合。
在实际设计中,我们将整个过程分解为任务,并判断哪些任务适合CPU、GPU或FPGA。为此,我们分析每个任务的并行性、并行程度以及一个步骤对另一个步骤的依赖程度。从经验来看,任务处理模式可以分为几类。我们从基于这些模式的架构模板(类似于蓝图)开始,然后进行微调。
在实际设计中,我们将整个过程分解为任务,并判断哪些任务适合CPU、GPU或FPGA。为此,我们分析每个任务的并行性、并行程度以及一个步骤对另一个步骤的依赖程度。从经验来看,任务处理模式可以分为几类。我们从基于这些模式的架构模板(类似于蓝图)开始,然后进行微调。
通过连接芯片实现对大规模数据的扩展。(图片提供:张山研究室)
大塚
所以,即使模式在某种程度上标准化了,仍然需要为特定任务进行微调,对吗?在使这种调整更顺畅之前,瓶颈在哪里?
张山
这取决于一次输入多少数据以及需要多快处理等约束条件。我们编程系统以查看输入数据,并判断“如果是这种工作负载,就这样优化”。如果数据流很重,我们加深流水线;如果范围很广,我们增加空间单元。如果充分融入这种逻辑,系统应该能够自动适应和调整。从C语言程序合成FPGA电路有时可能需要10小时。为了减少这种编译时间,我们与Altera日本团队合作,将部分重构融入OneAPI*2,通过技术协作来提高FPGA设计的效率。
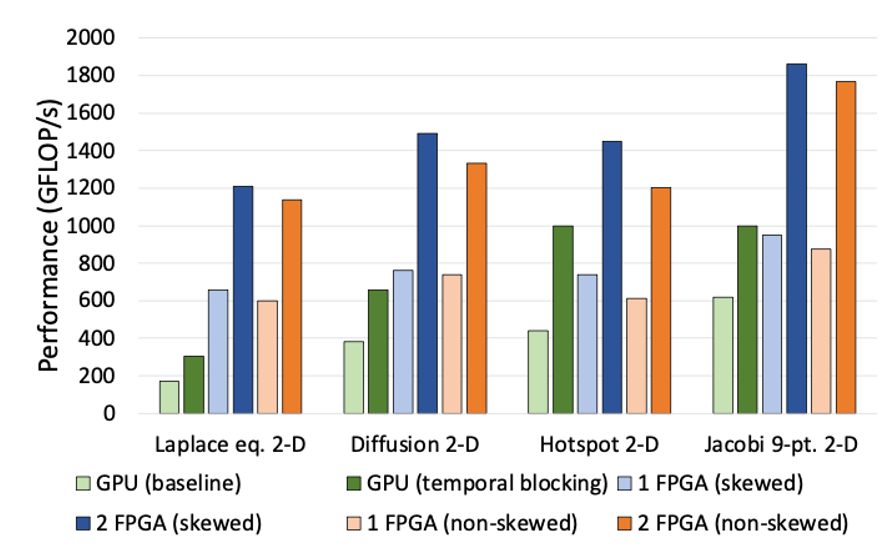
与GPU的基准测试比较。连接多个FPGA可线性提升性能,仅用两块即可大幅超越GPU的处理能力。(图片提供:张山研究室)
大塚
我觉得另一个值得一提的是FPGA的可扩展性——连接多个芯片后,它们就像一个巨大的电路一样运行,对吗?在我们的云设置中,这意味着我们可以提供计算实例,用户可以通过多个单元使用此功能。您预测会有什么发展?
张山
FPGA的一个优势是扩展非常简单——只需用电缆连接并调整设置。这一点其实并不广为人知。例如,对于巨大的图结构、气候模型的10,000×10,000网格的大型矩阵计算,或量子化学中需要处理从万亿分之一到万亿的四倍精度计算,CPU和GPU随着问题规模的增加速度会下降。但对于FPGA,只需用电缆连接多个单元,它们就像一个巨大的芯片一样运行,几乎是无缝的,规模增大时速度也不会下降。对于科学计算或特殊任务来说,这是革命性的。
大塚
确实如此。张山教授,非常感谢您的宝贵见解。今后也请多多关照。
*1 动态加速器:根据计算内容动态切换处理器配置,提高处理速度和能效的技术。
*2 OneAPI:英特尔开发的用于硬件编程的开放语言。
*2 OneAPI:英特尔开发的用于硬件编程的开放语言。
张山昌论信息科学博士。东北大学信息科学研究科智能集成系统领域教授。日本使用FPGA(现场可编程门阵列)进行应用专用超级计算的顶尖专家。