<<
Entretien avec un conseiller : Vers une plateforme de calcul ultra-rapide accessible à tous — ThinkX et l’Université de Tohoku envisagent le calcul intensif avec l’IA et les FPGA : Entretien avec le professeur Masanori Hariyama
19 février 2025
Masanori Hariyama, Professeur de systèmes intégrés intelligents, École supérieure des sciences de l’information, Université de Tohoku
Cette fois, nous avons discuté avec le professeur Masanori Hariyama, du domaine des systèmes intégrés intelligents de l’Université de Tohoku, un expert de premier plan dans la recherche appliquée sur les semi-conducteurs FPGA (Field Programmable Gate Array), un type de circuit intégré pour le calcul intensif, et conseiller de ThinkX.


 Masanori Hariyama
Masanori Hariyama
Docteur en sciences de l’information. Professeur à l’École supérieure des sciences de l’information, Systèmes intégrés intelligents, Université de Tohoku. Expert de premier plan au Japon en superinformatique spécifique aux applications utilisant des FPGA (Field-Programmable Gate Arrays).
Kazuki Otsuka (ci-après Otsuka)
Aujourd’hui, nous discutons avec le professeur Masanori Hariyama de l’Université de Tohoku, collaborateur et conseiller du projet de ThinkX 'Système d’Accélérateur Dynamique*1 pour l’Analyse en Temps Réel des Big Data dans la Recherche Avancée'—ou, plus simplement, 'un superordinateur alimenté par l’IA et des semi-conducteurs spécialisés'.
Ce projet est développé comme une fonctionnalité clé du VN Machine Cloud, une plateforme de calcul pour la recherche avancée. L’objectif est de démocratiser le traitement des données complexes. Pensez à des tâches comme la gestion de flux incessants d’images provenant de télescopes géants (imaginez des téraoctets de données stellaires), l’analyse en temps réel pour la chimie quantique et le séquençage ADN. Actuellement, les experts construisent ces solutions sur mesure, mais notre ambition est d’ouvrir grand cette porte. Imaginez des chercheurs sans expertise en calcul terminant en trois jours des calculs qui prennent six mois ou réduisant de moitié les coûts d’électricité. Nous pensons que cette solution a une valeur particulière pour des défis interdisciplinaires à grande échelle comme la modélisation climatique ou l’énergie durable.
Pour commencer, professeur Hariyama, pourriez-vous nous parler de votre domaine d’expertise et de vos projets récents ?
Ce projet est développé comme une fonctionnalité clé du VN Machine Cloud, une plateforme de calcul pour la recherche avancée. L’objectif est de démocratiser le traitement des données complexes. Pensez à des tâches comme la gestion de flux incessants d’images provenant de télescopes géants (imaginez des téraoctets de données stellaires), l’analyse en temps réel pour la chimie quantique et le séquençage ADN. Actuellement, les experts construisent ces solutions sur mesure, mais notre ambition est d’ouvrir grand cette porte. Imaginez des chercheurs sans expertise en calcul terminant en trois jours des calculs qui prennent six mois ou réduisant de moitié les coûts d’électricité. Nous pensons que cette solution a une valeur particulière pour des défis interdisciplinaires à grande échelle comme la modélisation climatique ou l’énergie durable.
Pour commencer, professeur Hariyama, pourriez-vous nous parler de votre domaine d’expertise et de vos projets récents ?
Professeur Masanori Hariyama (ci-après Hariyama)
Mon expertise porte sur les superordinateurs spécifiques aux applications utilisant des FPGA. FPGA signifie Field-Programmable Gate Arrays. C’est un type de semi-conducteur qui peut être reprogrammé après fabrication en modifiant ses circuits ou ses fonctions de calcul par programmation. Cette flexibilité le rend utile lorsque, par exemple, vous devez accélérer des processus spécifiques ou réduire la consommation d’énergie. De plus, en changeant le programme, les FPGA peuvent s’adapter à diverses applications, permettant la production en masse d’un seul type de puce, ce qui réduit considérablement les coûts de fabrication.
Parmi nos développements, on trouve des solveurs pour le recuit quantique, des simulations d’ordinateurs quantiques à base de portes, le traitement du langage naturel et des séquenceurs ADN.
Bien que les FPGA offrent ces avantages, concevoir des circuits optimisés pour des applications spécifiques n’est pas toujours simple, contrairement aux CPU ou GPU à usage général.
Parmi nos développements, on trouve des solveurs pour le recuit quantique, des simulations d’ordinateurs quantiques à base de portes, le traitement du langage naturel et des séquenceurs ADN.
Bien que les FPGA offrent ces avantages, concevoir des circuits optimisés pour des applications spécifiques n’est pas toujours simple, contrairement aux CPU ou GPU à usage général.
Traitement en temps réel de l’algorithme de codage/décodage H.266 sur de gros fichiers vidéo. (Image fournie par : Laboratoire Hariyama)
Otsuka
La technologie FPGA a beaucoup progressé, n’est-ce pas ? Xilinx a été racheté en 2012, et Altera en 2022. Notre approche combine les FPGA avec des modèles de langage à grande échelle—l’IA, en somme—pour identifier des motifs de calcul standardisés. Plutôt que de tout écrire dans des langages détaillés comme OpenCL ou C++, nous construisons un langage de plus haut niveau. L’idée est d’automatiser le processus pour que le système trouve lui-même la bonne manière d’appliquer les calculs. Pouvez-vous expliquer en détail comment cela fonctionne avec les FPGA ?
Hariyama
L’optimisation des calculs avec les FPGA se résume à deux grands motifs : le parallélisme spatial et le pipelining. Le parallélisme spatial, c’est comme avoir plusieurs travailleurs effectuant la même tâche en même temps—plusieurs unités exécutent la même tâche sur différentes données simultanément. Le pipelining, en revanche, ressemble à une chaîne de montage en usine : un travailleur passe les résultats au suivant, chacun gérant une tâche différente, permettant ainsi d’exécuter plusieurs tâches en parallèle. En pratique, nous combinons ces deux approches pour créer des motifs architecturaux bénéfiques. Par exemple, nous pourrions utiliser le parallélisme spatial à une étape du pipeline ou imbriquer des pipelines dans le parallélisme spatial. La clé est de trouver la combinaison optimale de ces motifs pour une tâche donnée.
Dans la conception réelle, nous décomposons l’ensemble du processus en tâches et décidons lesquelles conviennent le mieux aux CPU, GPU ou FPGA. Pour cela, nous analysons le parallélisme de chaque tâche, son degré de parallélisation et la dépendance d’une étape par rapport à une autre. D’après notre expérience, les motifs de traitement des tâches se répartissent en quelques catégories. Nous partons de modèles architecturaux basés sur ces motifs—comme des plans—et les affinons à partir de là.
Dans la conception réelle, nous décomposons l’ensemble du processus en tâches et décidons lesquelles conviennent le mieux aux CPU, GPU ou FPGA. Pour cela, nous analysons le parallélisme de chaque tâche, son degré de parallélisation et la dépendance d’une étape par rapport à une autre. D’après notre expérience, les motifs de traitement des tâches se répartissent en quelques catégories. Nous partons de modèles architecturaux basés sur ces motifs—comme des plans—et les affinons à partir de là.
Mise à l’échelle pour de grands ensembles de données en reliant des puces. (Image fournie par : Laboratoire Hariyama)
Otsuka
Donc, même si les motifs sont quelque peu standardisés, il faut encore les ajuster pour des tâches spécifiques, c’est bien ça ? Quels sont les goulots d’étranglement pour rendre cet ajustement plus fluide ?
Hariyama
Cela dépend des contraintes, comme la quantité de données entrantes à la fois et la vitesse à laquelle elles doivent être traitées. Nous programmons le système pour qu’il examine les données entrantes et décide : « Pour cette charge de travail, optimise comme ceci ». Si le flux de données est lourd, nous approfondissons le pipeline ; s’il est large, nous ajoutons plus d’unités spatiales. Avec suffisamment de logique intégrée, le système peut s’adapter et s’ajuster automatiquement. La synthèse de circuits FPGA à partir de code C peut prendre environ 10 heures dans certains cas. Pour réduire ce temps de compilation, nous collaborons avec Altera Japan, en intégrant une reconfiguration partielle dans OneAPI*2 et en apportant des contributions techniques pour rationaliser la conception des FPGA.
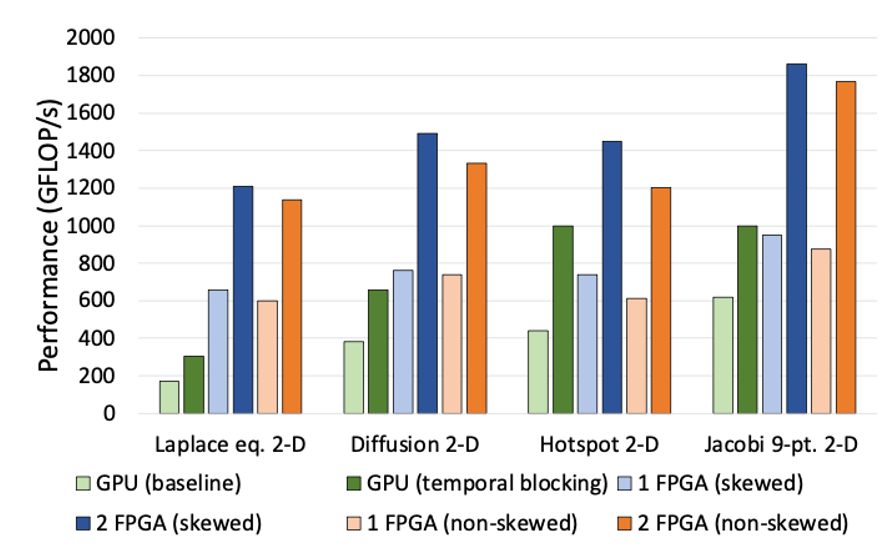
Comparaison des performances avec les GPU. La connexion de plusieurs FPGA améliore les performances de manière linéaire, dépassant largement les GPU avec seulement deux unités. (Image fournie par : Laboratoire Hariyama)
Otsuka
Une autre chose que je trouve remarquable, c’est la scalabilité des FPGA connectés. Relier plusieurs puces les fait fonctionner comme un circuit géant, non ? Dans notre configuration cloud, cela signifie que nous fournissons des instances de calcul où les utilisateurs peuvent exploiter cette fonctionnalité sur plusieurs unités. Quels développements prévoyez-vous ?
Hariyama
L’un des atouts des FPGA est la facilité avec laquelle ils peuvent être mis à l’échelle—juste les connecter avec des câbles et ajuster la configuration. Ce n’est pas très connu. Par exemple, pour des structures de graphes massives, des calculs matriciels énormes pour des modèles climatiques (pensez à des grilles de 10 000 x 10 000), ou des calculs en quadruple précision pour la chimie quantique gérant des nombres allant de billionièmes à billions, les CPU et GPU ralentissent à mesure que le problème grandit. Mais avec les FPGA, connecter plusieurs unités avec des câbles les fait fonctionner comme une seule puce géante. C’est presque transparent, et la vitesse ne diminue pas avec l’échelle. Pour le calcul scientifique ou les tâches spécialisées, c’est révolutionnaire.
Otsuka
Tout à fait. Professeur Hariyama, merci pour cette discussion précieuse. Nous avons hâte de poursuivre cette collaboration.
*1 Accélérateur Dynamique : Technologie qui reconfigure dynamiquement les configurations des processeurs selon les besoins de calcul, améliorant la vitesse et l’efficacité énergétique.
*2 OneAPI : Un langage ouvert pour la programmation matérielle développé par Intel.
*2 OneAPI : Un langage ouvert pour la programmation matérielle développé par Intel.
Masanori HariyamaDocteur en sciences de l’information. Professeur à l’École supérieure des sciences de l’information, Systèmes intégrés intelligents, Université de Tohoku. Expert de premier plan au Japon en superinformatique spécifique aux applications utilisant des FPGA (Field-Programmable Gate Arrays).