<<
Интервью с советником: К сверхбыстрой вычислительной платформе для всех — ThinkX и Университет Тохоку представляют суперкомпьютинг с ИИ и FPGA: Интервью с профессором Масанори Хариямой
19 февраля 2025 года
Масанори Харияма, профессор кафедры интеллектуальных интегрированных систем, Высшая школа информационных наук, Университет Тохоку
На этот раз мы побеседовали с профессором Масанори Хариямой из области интеллектуальных интегрированных систем Университета Тохоку, ведущим экспертом в области прикладных исследований полупроводников FPGA (Field Programmable Gate Array) — типа интегральных схем для суперкомпьютинга, а также советником ThinkX.


 Масанори Харияма
Масанори Харияма
Доктор наук (информатика). Профессор Высшей школы информационных наук, кафедра интеллектуальных интегрированных систем, Университет Тохоку. Ведущий эксперт в Японии по суперкомпьютингу для специфических приложений с использованием FPGA (Field-Programmable Gate Arrays).
Казуки Оцука (далее Оцука)
Сегодня мы беседуем с профессором Масанори Хариямой из Университета Тохоку, соавтором и советником проекта ThinkX 'Динамическая система ускорителей*1 для анализа больших данных в реальном времени в передовых исследованиях' — или, проще говоря, 'суперкомпьютер на базе ИИ и специализированных полупроводников'.
Этот проект разрабатывается как ключевая функция облака VN Machine Cloud, платформы вычислений для передовых исследований. Цель — сделать сложную обработку данных доступной для всех. Представьте задачи вроде обработки бесконечных потоков изображений с гигантских телескопов (представьте терабайты данных о звездах), анализа в реальном времени для квантовой химии и секвенирования ДНК. Сейчас эксперты создают эти решения на заказ, но наша цель — широко распахнуть эту дверь. Представьте себе исследователей без знаний в области вычислений, завершающих расчёты, которые занимают полгода, всего за три дня или сокращающих расходы на электроэнергию вдвое. Мы считаем, что это решение особенно ценно для крупномасштабных междисциплинарных задач, таких как моделирование климата или устойчивая энергетика.
Для начала, профессор Харияма, расскажите о вашей специальности и последних проектах.
Этот проект разрабатывается как ключевая функция облака VN Machine Cloud, платформы вычислений для передовых исследований. Цель — сделать сложную обработку данных доступной для всех. Представьте задачи вроде обработки бесконечных потоков изображений с гигантских телескопов (представьте терабайты данных о звездах), анализа в реальном времени для квантовой химии и секвенирования ДНК. Сейчас эксперты создают эти решения на заказ, но наша цель — широко распахнуть эту дверь. Представьте себе исследователей без знаний в области вычислений, завершающих расчёты, которые занимают полгода, всего за три дня или сокращающих расходы на электроэнергию вдвое. Мы считаем, что это решение особенно ценно для крупномасштабных междисциплинарных задач, таких как моделирование климата или устойчивая энергетика.
Для начала, профессор Харияма, расскажите о вашей специальности и последних проектах.
Профессор Масанори Харияма (далее Харияма)
Моя специальность — суперкомпьютеры для конкретных приложений с использованием FPGA. FPGA — это сокращение от Field-Programmable Gate Arrays. Это тип полупроводника, который можно перепрограммировать после производства, изменяя его схемы или вычислительные функции через программирование. Такая гибкость делает его полезным, например, когда нужно ускорить определённые процессы или снизить энергопотребление. Кроме того, изменяя программу, FPGA можно адаптировать к различным приложениям, что позволяет массово производить один тип чипа, значительно снижая затраты на производство.
Примеры наших разработок включают солверы для квантового отжига, симуляции квантовых компьютеров на основе вентилей, обработку естественного языка и секвенсоры ДНК.
Хотя у FPGA есть эти преимущества, проектирование схем, оптимизированных для конкретных приложений, не всегда просто, в отличие от универсальных процессоров или графических процессоров.
Примеры наших разработок включают солверы для квантового отжига, симуляции квантовых компьютеров на основе вентилей, обработку естественного языка и секвенсоры ДНК.
Хотя у FPGA есть эти преимущества, проектирование схем, оптимизированных для конкретных приложений, не всегда просто, в отличие от универсальных процессоров или графических процессоров.
Обработка в реальном времени алгоритма кодирования/декодирования H.266 на больших видеофайлах. (Изображение предоставлено: лаборатория Хариямы)
Оцука
Технология FPGA сильно продвинулась, верно? Xilinx был приобретён в 2012 году, а Altera — в 2022. Наш подход сочетает FPGA с крупномасштабными языковыми моделями — по сути, ИИ — для поиска стандартных вычислительных паттернов. Вместо того чтобы описывать всё в детальных языках вроде OpenCL или C++, мы создаём язык более высокого уровня. Идея в том, чтобы автоматизировать процесс, чтобы система сама определяла правильный способ применения вычислений. Как это работает с FPGA, можете объяснить подробнее?
Харияма
Оптимизация вычислений в FPGA сводится к двум основным паттернам: пространственный параллелизм и конвейерная обработка. Пространственный параллелизм — это как несколько рабочих, выполняющих одну задачу одновременно: несколько блоков выполняют одну и ту же задачу над разными данными параллельно. Конвейерная обработка, напротив, похожа на сборочную линию на заводе: один рабочий передаёт результат следующему, каждый выполняет разные задачи, что позволяет параллельно выполнять несколько задач. На практике мы комбинируем эти подходы, чтобы создать полезные архитектурные паттерны. Например, мы можем использовать пространственный параллелизм на определённом этапе конвейера или вкладывать конвейеры в пространственный параллелизм. Ключ в том, чтобы найти оптимальную комбинацию этих паттернов для конкретной задачи.
В реальном проектировании мы разбиваем весь процесс на задачи и определяем, какие из них лучше подходят для процессоров, графических процессоров или FPGA. Для этого мы анализируем параллелизм каждой задачи, степень её параллелизации и зависимость одного шага от другого. По опыту, паттерны обработки задач делятся на несколько категорий. Мы начинаем с шаблонов архитектуры, основанных на этих паттернах — своего рода чертежей — и дорабатываем их.
В реальном проектировании мы разбиваем весь процесс на задачи и определяем, какие из них лучше подходят для процессоров, графических процессоров или FPGA. Для этого мы анализируем параллелизм каждой задачи, степень её параллелизации и зависимость одного шага от другого. По опыту, паттерны обработки задач делятся на несколько категорий. Мы начинаем с шаблонов архитектуры, основанных на этих паттернах — своего рода чертежей — и дорабатываем их.
Масштабирование для больших наборов данных путём соединения чипов. (Изображение предоставлено: лаборатория Хариямы)
Оцука
То есть, даже если паттерны в какой-то степени стандартизированы, всё равно нужно их подстраивать под конкретные задачи, верно? Какие узкие места мешают сделать эту настройку более плавной?
Харияма
Это зависит от ограничений, таких как объём поступающих данных и скорость, с которой их нужно обработать. Мы программируем систему так, чтобы она смотрела на входные данные и решала: «Для такой нагрузки оптимизируй вот так». Если поток данных тяжёлый, мы углубляем конвейер; если он широкий, добавляем больше пространственных блоков. Если встроить достаточно такой логики, система сможет автоматически адаптироваться и корректироваться. Синтез схем FPGA из кода на C иногда занимает около 10 часов. Чтобы сократить это время компиляции, мы сотрудничаем с Altera Japan, внедряя частичную реконфигурацию в OneAPI*2 и внося технический вклад для упрощения проектирования FPGA.
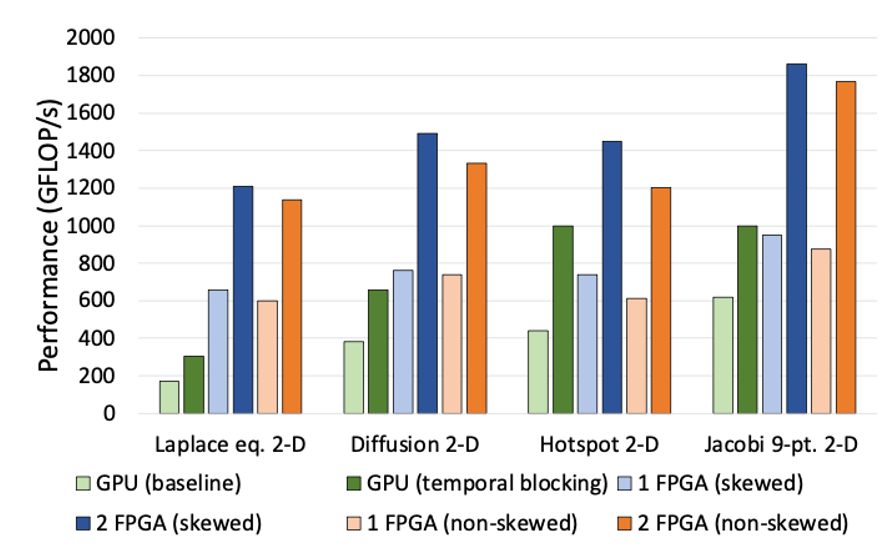
Сравнение производительности с GPU. Соединение нескольких FPGA обеспечивает линейное улучшение, превосходя возможности GPU всего с двумя блоками. (Изображение предоставлено: лаборатория Хариямы)
Оцука
Ещё одна вещь, которую я считаю достойной внимания, — это масштабируемость соединения FPGA. Соединение нескольких чипов заставляет их работать как одну огромную схему, верно? В нашей облачной системе это означает, что мы предоставляем вычислительные экземпляры, где пользователи могут использовать эту функцию на нескольких блоках. Какие перспективы вы видите?
Харияма
Одно из преимуществ FPGA — это невероятная простота масштабирования: достаточно соединить их кабелями и настроить систему. Это не очень известно. Например, для массивных графовых структур, огромных матричных вычислений для климатических моделей (представьте сетку 10,000 × 10,000) или вычислений с четырёхкратной точностью для квантовой химии, где нужны числа от триллионных до триллионов, скорость процессоров и графических процессоров падает с ростом задачи. Но с FPGA соединение нескольких блоков кабелями позволяет им работать как одному гигантскому чипу. Это почти бесшовно, и скорость не снижается при увеличении масштаба. Для научных вычислений и специализированных задач это революционно.
Оцука
Совершенно верно. Профессор Харияма, спасибо за ценную беседу. Надеемся на дальнейшее сотрудничество.
*1 Динамический ускоритель: технология, которая динамически изменяет конфигурацию процессора в зависимости от вычислительных задач, повышая скорость и энергоэффективность.
*2 OneAPI: открытый язык для программирования оборудования, разработанный Intel.
*2 OneAPI: открытый язык для программирования оборудования, разработанный Intel.
Масанори ХариямаДоктор наук (информатика). Профессор Высшей школы информационных наук, кафедра интеллектуальных интегрированных систем, Университет Тохоку. Ведущий эксперт в Японии по суперкомпьютингу для специфических приложений с использованием FPGA (Field-Programmable Gate Arrays).